0 引言
如何应对气候变化是当前人类社会面临的巨大挑战,是备受社会关注的热点问题,高精度、高分辨率的气候数据是量化气候变化对农业、生态、水文等影响的基础。全球气候模式可以提供气候变化的信息,但全球气候模式数据空间分辨率较低,仅为100—300 km,很难应用于农业、生态、水文等领域。因此经常需要使用各种方法进行降尺度,以提高气候数据的空间分辨率。常用的降尺度方法包括动力降尺度和统计降尺度。
动力降尺度是较为常见的降尺度方法,应用广泛,但动力降尺度也有着明显的缺点[1 ] 。动力降尺度使用全球气候模式的结果作为初始场和边界条件,在次网格尺度响应区域信息,从而增强大气环流的细节,达到降尺度的目的[2 ] 。动力降尺度的优势是:有明确的物理意义,物理过程与现实能保持较好的一致性,并且能捕捉极端事件[2 ] 。但缺点是需要较大的计算资源,模型不容易转移到新的区域,并且复杂地形下垫面参数(如海拔、土地利用等)的精度影响动力降尺度模型[3 ] 。
统计降尺度作为另一种较为常见的降尺度方法,虽然无法很好体现其物理过程和机制,但是计算效率较高,模型不受地区限制,同时可以输出气候模式无法输出的变量,适用于复杂地形条件下的小区域降尺度研究。统计降尺度主要分为3类:传递函数法,天气分类法,随机天气发生器[3 ] 。 其中传递函数法是较为常见的空间降尺度方法,通过建立历史观测资料和气候模式输出要素间的统计关系,并通过独立的检验期验证,再将这种关系应用于气候模式输出的未来气候要素,预估出关心区域的未来气候变化情景[4 ] ,以达到订正模式数据并降尺度的目的。常见的统计降尺度方法有Delta[5 ] 、Quantile Mapping[6 ] 、Bias-Correction and Spatial Downscaling[7 ] 、Bias-Correction and Climate Imprint[7 ] 、Bias Correction Constructed Analogues with Quantile Mapping Reordering[7 ] 等。
机器学习是被广泛应用的一种技术手段,主要用于解决分类和回归两类问题。机器学习现已被应用于大气科学领域:基于机器学习的天气气候预报技术、多源数据融合方法的发展及高分辨率气象数据的研制、数值模式与机器学习融合技术、气候事件物理机制解释、天气及气候变化的影响及辅助决策模型等。机器学习有自动捕捉空间特征的能力,这有利于复杂地形下的降尺度数据集,有很大的探索空间。机器学习模型通过计算机学习数据中的统计规律,得到线性或非线性的统计关系,再将这种统计关系应用到未来数据,以达到降尺度的目的。还有一些方法也被用到了统计降尺度中:Quan等[8 ] 使用长短时记忆网络对越南红河三角洲降水降尺度;Jing等[9 ] 使用支持向量回归和随机森林等模型对中国北方降水数据进行降尺度研究;Wang等[10 ] 使用贝叶斯回归和支持向量机对澳大利亚气温和降水进行降尺度研究。
石羊河是甘肃省河西走廊内流水系的第三大河,是中国较为重要的内陆河。近年来由于气候变化和人类活动的影响,其生态环境及水资源合理利用的问题引起广泛关注,例如有学者基于天气发生器模拟了未来降水的变化[11 ] ,以及气候变化对石羊河流域的影响[12 -13 ] 等。但是,关于石羊河流域未来气候变化的数据以及影响研究较少。因此,本研究旨在探索简单、可靠和可操作降尺度方法,为区域气候变化研究提供基础数据。
本研究选择包括传统统计模型和机器学习模型在内共计10种方法,在石羊河流域的4个站点进行气温和降水的降尺度研究。降尺度研究的训练期为1960—1990年,检验期为1991—2005年,未来输出结果为2006—2100年。并通过检验期的精度指标筛选模型,将筛选后的多模型平均得到未来RCP8.5和RCP4.5情景(基于CMIP5下针对东亚的区域气候产品)下各站点的气温和降水情况。
1 研究区与数据
1.1 研究区
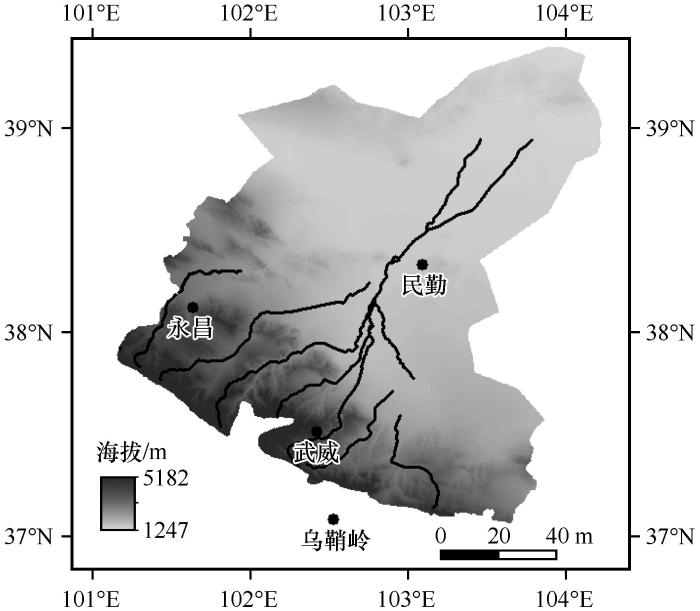
石羊河位于甘肃省河西走廊东部,乌鞘岭以西,源于南部祁连山,消失于民勤盆地北部(36°—39°N、101°—104°E)。流域内地形复杂,包括冰川、积雪、森林、沙漠、河流、城镇、耕地等多种土地类型,海拔1 247—5 128 m[13 ] ,是研究统计降尺度模型适用性的理想区域,具体信息见图1 。本研究选择流域内4个站点(武威、乌鞘岭、民勤和永昌)进行降尺度研究,站点主要信息见表1 [12 ] 。
图1
图1
石羊河流域海拔
Fig.1
Dem map of Shiyang River Basin
1.2 模式数据
本研究选用HadGEM3-RA模式数据[14 ] ,数据源为韩国国家气象研究所(National Institute of Meteorological Research)(http://cordex-ea.climate.go.kr/cordex/ )。该模型是the Coupled Model Intercomparison Project Phase 5 (CMIP5)项目[15 ] 下针对东亚的区域气候产品,已广泛用于气候评估研究[16 ] 。模式数据时间分辨率为1 d,空间分辨率为0.44°,本研究选择月平均数据。包括历史时期(1960—2005年)数据与RCP4.5情景[17 ] 下预测的未来时期气候模式数据(2006—2100年),RCP8.5情景[18 ] 下预测的未来时期气候模式数据(2006—2100年)。本研究选取模式中8个被常用于降尺度模型的变量[19 ] (表2 )。时间分段设置:训练期为1960—1990年,检验期为1991—2005年,预测期为2006—2100年。
1.3 站点实测数据
本研究选用永昌、武威、民勤、乌鞘岭(表3 )4个站点的实测数据,数据来自国家气象信息中心,数据名称为中国地面国际交换站气候资料日值数据集(V3.0),实测数据时间分辨率为1 d。本研究选取月平均气温和月降水量,选取1960—2005年总计46年数据。时间分段设置:训练期为1960—1990年,检验期为1991—2005年。
2 方法
本研究分别在4个站点进行多种降尺度模型比较。方法包括2种传统降尺度模型(反距离权重法结合分位数映射法、多元线性回归),4种机器学习模型(支持向量回归、人工神经网络、极限学习机、卷积长短时记忆网络),以及2种数据标准化方法(Z-score法和Minmax法)。利用站点气温和降水分别比较多种模型降尺度结果。各模型名称简写见表4 。
2.1 降尺度模型
本研究涉及分位数映射法、多元线性回归法,以及4种机器学习模型结合2种标准化方法,共计10种模型在气温和降水降尺度研究中应用。
2.1.1 分位数映射法
分位数映射法通过匹配训练期模式数据和观测数据的概率分布函数建立传递函数,再将传递函数运用到预测期模式数据[5 -6 ,20 ] 。原理是将预测期模式数据匹配到训练期观测数据的概率分布函数[21 ] ,并假设训练期的传递函数在预测期同样适用。
概率分布函数在分位数映射法中用来描述模式数据和观测数据的分布方式,常见的有理论概率分布和经验累积概率分布。理论概率分布函数对极值的订正效果较差,另外如当观测和模式气温数据不满足正态分布时,订正效果会不明显[22 ] 。经验累积概率分布函数中参数转换对于模式模拟的误差有较好的改善效果[23 ] ,并能够较好地描述模式数据和观测数据的分布方式。综上本研究选取经验累积概率分布函数。
传递函数在分位数映射法中用来建立训练期模式数据和观测数据的函数关系,常见的有参数函数和非参数函数。其中参数转换函数对于模式模拟的误差有较好的改善效果,例如线性函数、指数函数。非参数转换适用性更广泛,不需要对原始数据做前提假设[22 ] ,例如单调三次样条插值法、局部线性最小二乘回归法+线性插值法、三次光滑样条拟合法+广义交叉验证光滑参数法[23 ] 。本研究是月尺度数据间的函数转换,所以选取较为简单的一次线性函数作为传递函数。
(1) 分别建立训练期模式数据和实测数据的经验累积分布函数。
(2) 匹配训练期模式数据和观测数据的经验累积分布函数,建立传递函数。
Y = F o b s - 1 ( F m , b a s e ( X m , f u t ) ) (1)
式中:F obs 是训练期实测数据的经验累积分布函数;Fm ,base 是训练期模式数据的经验累积分布函数;Xm ,fut 是预测期模式数据。
由于模式数据是网格化的,无法直接使用分位数映射法,所以本研究选用反距离权重法作为降尺度方法,将模式数据插值到站点。反距离权重法是距离倒数乘方格网化方法,是一个加权平均插值法,可以确切的或者圆滑的方式插值。方次参数控制着权重系数如何随着离开一个格网结点距离的增加而下降。对于一个较大的方次,较近的数据点被给定一个较高的权重份额,对于一个较小的方次,权重比较均匀地分配给各数据点[24 ] ,本次研究选取方次为2[25 ] 。
S i = ∑ k = 1 4 1 d i , k m ∑ j = i 4 1 d i , j m - 1 P k (2)
式中:Si 是站点内插后的数据;Pk 是格点k 数据;di 是格点到站点距离;m 是反比例系数,本次研究取m =2。
2.1.2 多元线性回归
多元线性回归是常见的统计学模型。假设训练期建立的预测量和预测因子的线性关系可以沿用到预测期,并且训练期实测数据的标准差和平均值没有变化直接运用到未来。原理是利用最小二乘法拟合预测因子和预测量。由于多个预测因子之间一定存在相关性,需要人为地筛选或构造,所以选择构造一些新的自变量,这些新的自变量由原有变量线性变换得到,可以反映原有变量所蕴含的基本信息。
本研究选择8种区域气候模式数据输出变量作为输入,以建立训练期各变量与目标(站点的气温、降水)间的线性关系。8种输入变量,根据物理关系及文献经验选取[19 ] 。主要包括3个步骤:
(1) 将自变量标准化(不受标准化方法影响,数据无量纲化即可)。
(2) 训练期预测量和标准化后的自变量建立线性关系。
本文使用的多元线性回归公式如下,预测因子根据大气科学的基本常识选取[19 ] :
Y f P s ,Z g500 ,H uss ,T as ,H fls ,H fss ,R lds ,R sds )(3)
2.1.3 支持向量回归
支持向量回归属于支持向量机,该模型主要应用于回归问题。支持向量回归的核心思想是寻找一条最佳拟合曲线,在容忍偏差范围内,曲线包含尽可能多的数据点。回归方程的数学描述为[26 ] :
f ( x ) = w T φ ( x ) + b (4)
m i n w , b , ξ , ξ * 1 2 w T w + C ∑ i = 1 n ( ξ i + ξ i * ) (5)
s . t . y i - w , x i + b ε ≤ + ξ i w , x i + b - y i ≤ ε + ξ i * ( i = 1,2 , … , l ) ξ i , ξ i * ≥ 0 (6)
式中:l 为样本数;xi 和yi 分别为训练集的输入和输出数据;n 为总样本数;ξi 和ξi * 分别为训练误差上界和下界;ε 为不敏感损失因子;C 为正则常量。
f x , a i , a i * = ∑ i = 1 n ( a i - a i * ) K ( x , x i ) + b (7)
式中:f (x ,ai ,a i * ai 为拉格朗日乘数;ai * 为拉尔朗日乘数;K (x,xi )为核函数。
2.1.4 人工神经网络
人工神经网络是受人类大脑结构启发得到的,该网络由一系列相互连接的神经元构成。网络内部不同神经元之间通过权重相连,神经元内设有激活函数和偏差。根据使用的激活函数和学习算法的不同,人工神经网络可以分为不同类别。人工神经网络的数学描述为[28 ] :
y i ( n ) = f ( ∑ j = 1 N w i j n , n - 1 y j n - 1 + θ i n ) (8)
式中:i 为第n 层的神经元;wi,j 为第n -1层神经元j 和第n 层神经元i 之间的权重;θi n 为第n-t 层神经元i 的偏差。
2.1.5 极限学习机
极限学习机也属于人工神经网络,是一类包含单个隐藏层的前馈神经网络[29 ] ,该算法最大的特点是在保证学习精度的前提下训练速度更快。极限学习机在训练模型前,首先随机初始化输入权重和偏差,同时确定输出矩阵。不同于传统的神经网络,极限学习机在迭代时不需要更新全部参数,仅通过输出矩阵求解相应方程组就能快速训练模型。极限学习机的损失函数描述为:
E = ∑ j = 1 N ∑ i = 1 L β i g W i · X j + b i - t j 2 (9)
式中:N 为输入神经元数量;L 为隐藏层神经元数量;βi 为隐藏层和输出层之间权重;g(x )为激活函数;Wi 为输入层和隐藏层之间权重;Xj 为输入数据;bi 为偏差;tj 为输出数据。
2.1.6 卷积长短时记忆网络
长短时记忆网络是一种特殊的循环神经网络,用来解决长序列训练过程中的梯度消失和梯度爆炸问题。主要包括遗忘阶段、选择输入阶段、输出阶段[30 ] 。
卷积长短时记忆网络不仅具有长短时记忆网络的时序建模能力[30 ] ,而且还能像卷积神经网络一样刻画局部特征[31 ] 。卷积长短时记忆网络是将基础的长短时记忆网络的输入和传递过程的前馈式计算替换成卷积的形式,即输入与各个门之间的连接由前馈式替换成了卷积,同时状态与状态之间也换成了卷积运算。长短时记忆网络的输入门、遗忘门、输出门保持不变。输入门决定细胞状态中存储的信息,遗忘门决定细胞状态中被遗忘的信息,输出门决定最终输出。单个神经元的计算过程为:①输入数据,输入门激活,计算输入细胞的信息。②如果遗忘门激活,遗忘部分细胞中保留的历史状态。③输出门激活,计算神经元的输出信息,并更新细胞状态。每个神经元都包含上述3个门,在模型进行计算时,神经元内计算过程可以描述为[31 ] :
i t = σ ( W x i * X t + W h i * H t - 1 + W c i ∘ C t - 1 + b i ) (10)
f t = σ ( W x f * X t + W h f * H t - 1 + W c f ∘ C t - 1 + b f ) (11)
C t = f t ∘ C t - 1 + i t ∘ t a n h ( W x c * X t + W h c * H t - 1 + b c ) (12)
o t = σ ( W x o * X t + W h o * H t - 1 + W c o ∘ C t - 1 + b o ) (13)
H t = o t ∘ t a n h ( C t ) (14)
y t = W y m * H t + b y (15)
式中:x =(x 1 ,x 2 ,···,xt )为展开层数据;it 为输入门;ft 为遗忘门;Ct 为记忆细胞的激活矢量;ot 为输出门;Ht 为每个记忆块的激活矢量;W 为权重矩阵;b 为偏差矢量;∘为点积;*为卷积;σ 为激活函数,tanh 为激活函数,激活函数数学描述为[31 ] :
σ ( x ) = 1 / ( 1 + e - x ) (16)
t a n h ( x ) = ( e x - e - x ) / ( e x + e - x ) (17)
在长短时记忆网络的发展中出现了许多变种模型,如双向长短时记忆网络、门控循环单元等。其中双向长短时记忆网络利用历史信息和未来信息进行预测,门控循环单元减少了门的数量,模型原理与长短时记忆网络相似,此外还有与卷积神经网络结合的模型,如卷积长短时记忆网络和卷积门控循环单元。
2.1.7 机器学习模型的数据处理
本研究选用4种机器学习模型研究,机器学习模型的输入选择8种不同变量数据(表2 ),8种变量根据物理关系及文献经验选取[19 ] 。在输入机器学习模型前进行数据标准化处理,以消除单位等量纲的影响。然后将无量纲化的数据输入机器学习模型(支持向量回归模型取最优曲线,人工神经网络模型输入多个神经元,极限学习机模型输入隐藏层再输入多个神经元,卷积长短时记忆网络模型先输入卷积层再输入长短时记忆神经网络神经元),建立检验期自变量(无量纲的8种输入变量)与目标变量(站点气温、降水)间的关系,训练机器学习模型。将未来期数据输入训练好的模型,即可得到未来站点结果。
本研究对于机器学习模式的数据预处理选择了两种标准化方法,以达到将数据无量纲化,分别是Z-score标准化方法和Minmax标准化方法。其中Z-score标准化方法是将数据的平均值转换为0,标准差转换为1。
X 2 = X 1 - X ¯ σ X (18)
Minmax标准化方法是将数据转换到[0,1]区间。
X 2 = ( X 1 - X m i n ) / ( X m a x - X m i n ) (19)
式中:X 1 代表原始数据;X 2 代表结果;X ¯ X max 代表原始数据中最大值;X min 代表原始数据中最小值;σX 代表原始数据的标准差。
2.2 检验方法
多种方法订正数据后,使用相关系数和绝对误差反映各个方法对原始数据的订正情况[7 ] 。
绝对误差(MAE):是指校准值和比对值的代数差,绝对误差越小表示订正效果越好。
M A E = 1 n ∑ i = 1 n y i - x i (20)
相关系数(R ):用以反映变量之间相关关系密切程度的统计指标,相关系数越接近于1表示订正效果越好。
R = ∑ i = 1 n ( x i - x ¯ ) ( y i - y ¯ ) ∑ i = 1 n ( x i - x ¯ ) 2 ∑ i = 1 n ( y i - y ¯ ) (21)
式中:x 代表检验期输出结果,y 代表检验期实测数据。
3 结果
本研究在4个站点分别在RCP8.5和RCP4.5情景下对气温和降水降尺度模型进行研究。以检验期不同精度指标和检验期Quantile-Quantile图展示检验期结果,并筛选出多个表现优秀的模型作为待用模型,同时也展示了未来不同RCP情景下气温和降水的变化趋势。
3.1 检验期不同模型结果的精度对比
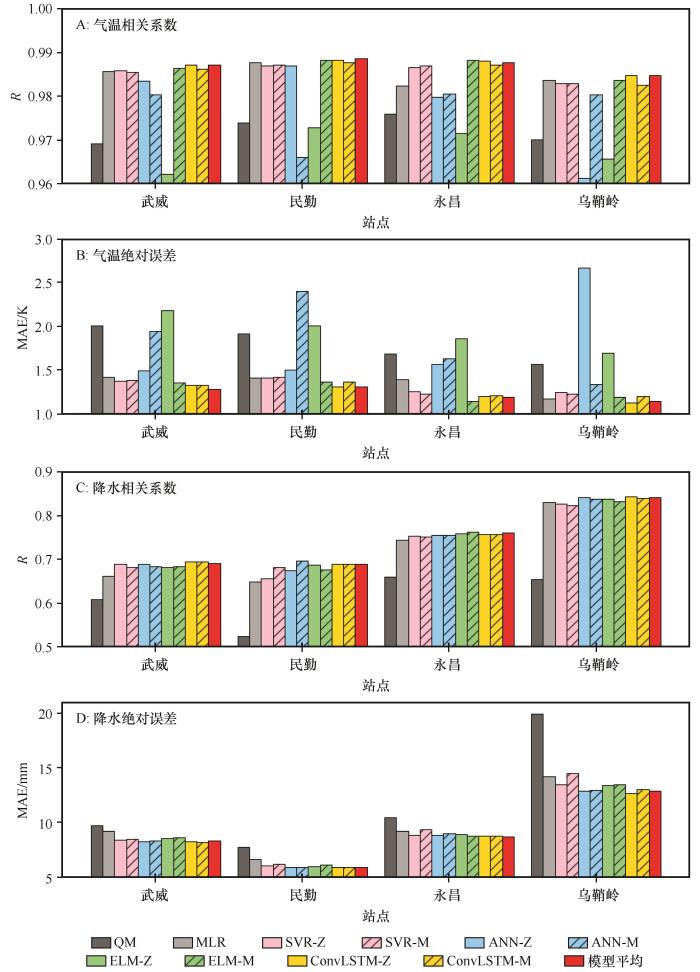
本研究分别在武威、民勤、永昌和乌鞘岭进行气温和降水多种降尺度模型比较研究,检验期结果精度见图2 (检验期相关系数均通过99%置信检验)。
图2
图2
4站点气温和降水检验期精度指标
Fig.2
The four stations temperature and precipitation test period accuracy indicators
检验期气温降尺度结果精度较好。10个降尺度模型分别在4个站点的气温降尺度研究中,相关系数均在0.96以上(图2 A)。但是,QM、ANN-Z、ANN-M和ELM-Z这4种模型在不同站点出现了较差的情况。例如ANN-M模型在武威的气温降尺度检验期相关系数为0.980,在民勤为0.966,在永昌为0.981,在乌鞘岭为0.980,说明ANN-M模型在民勤的表现较差。同样,在4个站点气温检验期的绝对误差也有相似的情况(图2 B),当模型的相关系数较低时绝对误差也较高(例如ANN-M模型在武威的气温降尺度检验期绝对误差为1.94 K,民勤为2.41 K,永昌为1.63 K,乌鞘岭为1.34 K)。在不考虑QM模型和ANN-Z,ANN-M,ELM-Z这4种模型时,剩余模型的相关系数均能达到0.98以上,绝对误差在1.50 K以内。
检验期降水降尺度结果精度在站点间整体差距较大,其中QM模型结果精度明显较低(图2 C、D)。从4个站点的降水降尺度相关系数可以看出,10个不同的降尺度模型分别在4个站点的降水降尺度研究中,相关系数均能达到0.5以上(图2 C)。机器学习结果明显优于传统统计模型。例如从乌鞘岭降水降尺度多模型对比中可以看出QM模型的精度明显低于其他模型,QM模型的相关系数为0.654,ANN-Z模型的相关系数为0.842,ConvLSTM-Z模型的相关系数为0.843,机器学习的模型精度明显优于传统模型。在4个站点的降水绝对误差同传统模型的绝对误差明显大于机器学习模型(图2 D)。以乌鞘岭为例,QM模型的降水绝对误差为19.93 mm,ANN-Z模型的降水绝对误差为12.92 mm,ConvLSTM-Z模型的绝对误差为12.71 mm。QM模型的降水绝对误差约比结果较好的ANN-Z模型的结果误差高30%左右。
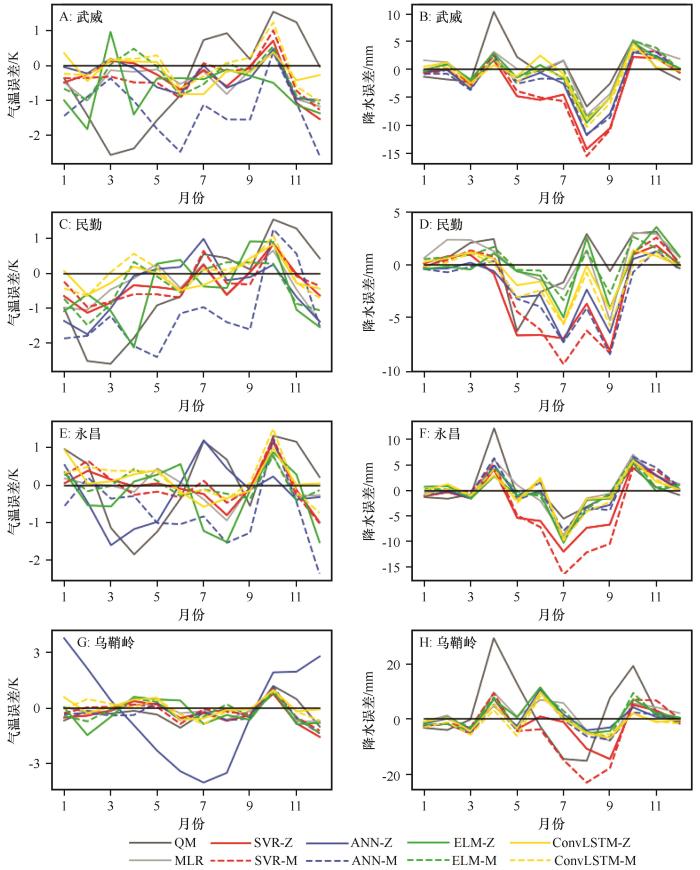
气温降尺度大部分模型的检验期分月误差小于1.00 K,其中QM、ANN-Z、ANN-M、ELM-Z模型分月误差较大。武威站QM模型在3月和10月误差较大,ANN-M模型在6和12月误差较大,ELM-Z模型在2月误差较大(图3 A)。民勤站QM模型在2、3、11月误差较大,ANN-M模型在5、9、10月误差较大,ELM-Z模型在4、12月误差较大(图3 C)。永昌站QM模型在4、7、10月误差较大,ANN-Z模型在3和7月误差较大,ANN-M模型在8月和12月误差较大,ELM-Z模型在8月和12月误差较大(图3 E)。乌鞘岭站ANN-Z模型在1、6、7、8、12月误差较大(图3 G)。
图3
图3
4站点气温和降水检验期年内变化误差
Fig.3
Monthly errror of temperature and precipitation over four stations during validation period
降水降尺度大部分模型的检验期分月误差与当地降水量呈正比,每一个站点大部分模型的降尺度误差呈现接近的趋势,其中QM、SVR-Z、SVR-M模型误差相对较大(图3 B、D、F、H)。在武威站除QM模型外,其他模型误差趋势接近,其中QM、SVR-Z、SVR-M模型误差相对较大(图3 B)。民勤站各模型整体在6—9月误差偏大,其中SVR-Z、SVR-M、ANN-Z、ANN-M模型误差较大(图3 D)。永昌站除QM、SVR-Z、SVR-M模型外,其他模型误差趋势接近,QM、SVR-Z、SVR-M模型误差相对较大(图3 F)。乌鞘岭站除QM、SVR-Z模型外,其他模型误差趋势接近,QM、SVR-Z、SVR-M模型误差相对较大(图3 H)。
3.2 经过模型筛选后多模型平均结果
由于4个站点气温和降水降尺度结果各有一些模型误差较大,基于检验期结果,选择MLR、SVR-Z、SVR-M、ELM-M、ConvLSTM-Z和ConvLSTM-M共计6个模型用于气温降尺度研究。选择MLR、ANN-Z、ANN-M、ELM-Z、ELM-M、ConvLSTM-Z和ConvLSTM-M共计7个模型用于降水降尺度研究。将筛选出的多模型平均,并与检验期实测数据比较,检验其精度。
可以看出筛选后的平均模型的精度稳定在较高的水平(图2 )。筛选后6模型的平均气温在各个站点的相关系数和绝对误差均能达到前3名,并与最好的模型差距较小(图2 A、B红色柱)。例如乌鞘岭站的相关系数,6模型平均十分接近最好的模型ConvLSTM-Z。又例如在武威站的绝对误差,6模型平均的绝对误差最小。可以看出筛选后7模型平均的降水,精度可以在多个模型中稳定在前三(图2 C、D红色柱)。
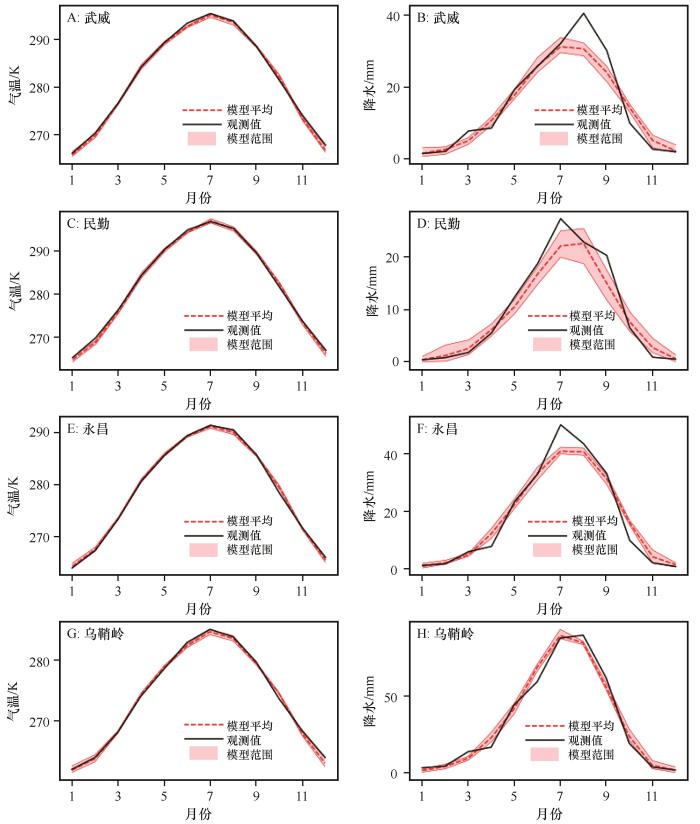
筛选后的平均模型在检验期分月比较中,气温整体模拟较好,降水在大部分时间模拟较好,仅在降水较多月份模拟稍差(图4 )。筛选后6模型平均气温的检验期分月平均结果与实测气温的对比发现(图4ACEG ),6 模型平均气温与实测气温非常接近,4站点最大误差仅为1.07 K。筛选后7模型平均降水结果与实测对比(图4 B、D、F、H),武威站8月和9月误差较大,8月误差为9.95 mm,9月误差为6.11 mm。民勤站7月和9月误差较大,7月误差为5.21 mm,9月误差为5.30 mm。永昌站7月误差较大,7月误差为9.12 mm。乌鞘岭站全年较好,6月误差为9.52 mm。
图4
图4
4站点气温和降水检验期年内循环结果
Fig.4
Monthly result of temperature and precipitation over four stations during validation period
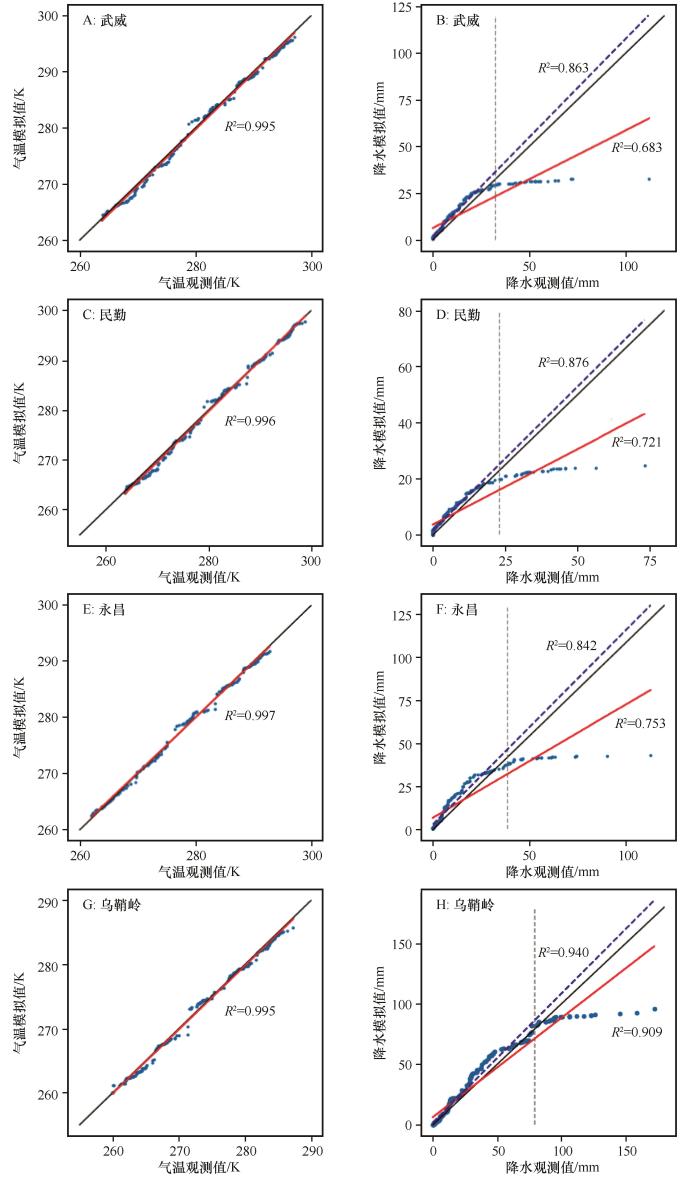
图5
图5
4站点气温和降水检验期Quantile-Quantile图(虚线为85%以下降水回归直线)
Fig.5
Monthly Quantile-Quantile plots of temperature and precipitation over four stations during validation period (The dotted line is the regression line for precipitation below 85%)
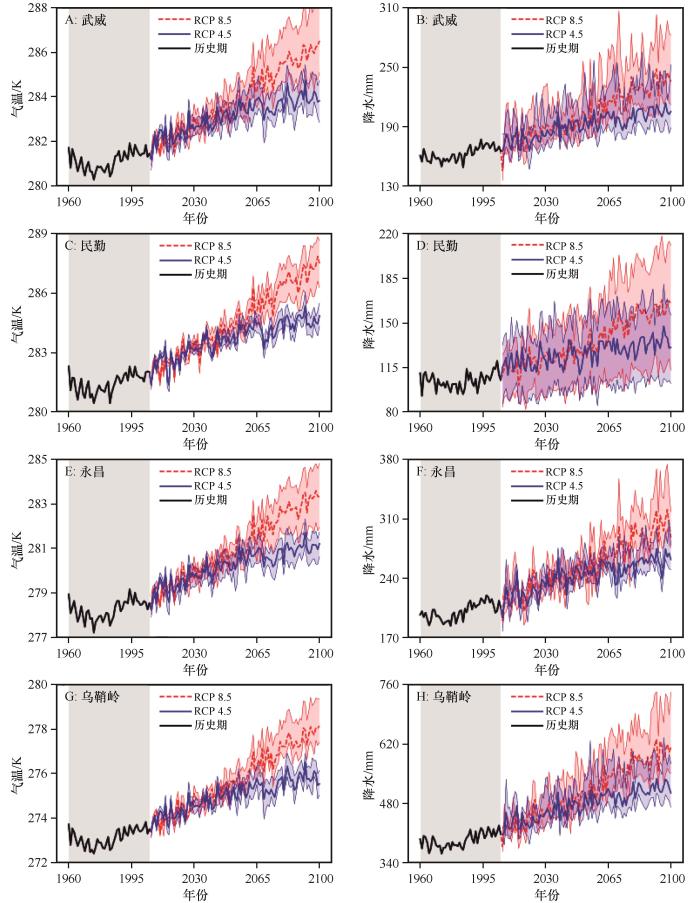
图6
图6
4站点气温和降水变化趋势
Fig.6
Changes in temperature and precipitation at four stations
筛选后的平均模型在分位数比较中,气温整体模拟较好,降水在85%以下模拟较好。筛选后6模型平均气温检验期Q-Q图结果较好,图中红线为拟合直线(图5 A、C、E、G),Q-Q图的R 2 均大于0.995。筛选后7模型平均降水检验期Q-Q图结果(图5 B、D、F、H),图中蓝色虚线为经验累积分布函数等于85%降水时取值,可以看出85%降水以下时平均模型模拟较好,大于85%降水时平均模型模拟偏小。图中红线为拟合直线,蓝线为小于85%降水拟合直线。可以看出85%降水以下时模型结果优于模型全局结果。红色R 2 为全部值的R 2 ,蓝色R 2 为85%降水以下的R 2 。武威站全局R 2 为0.683,85%降水以下时R 2 为0.863;民勤站全局R 2 为0.721,85%降水以下时R 2 为0.876;永昌站全局R 2 为0.753,85%降水以下时R 2 为0.842;乌鞘岭站全局R 2 为0.909,85%降水以下时R 2 为0.940。85%降水以下R 2 相对于全局R 2 平均提升了15%。85%降水以下时降水模拟的R 2 可以达到0.84以上,说明对于非极端降水筛选后的7模型平均降水模拟较好。
3.3 2006 -2100 年气温、降水预估
本研究选择1960—1990作为训练期,1991—2005作为检验期,2006—2100作为未来结果。未来结果分别在RCP4.5和RCP8.5情景下。未来结果由气温筛选后6模型平均和降水筛选后7模型平均构成。
未来气温呈现增加趋势,在2060年之前RCP8.5和RCP4.5情景增温趋势较为接近,在2060—2100年RCP8.5情景增温明显高于RCP4.5情景(图6 A、C、E、G)。增温情况本研究选择2091—2100年平均与检验期1991—2005年平均比较。武威站RCP4.5情景下气温距历史平均(灰带)增加了2.90 K,RCP8.5情景下增加了4.95 K。民勤站RCP4.5情景下气温距历史平均增加了3.17 K,RCP8.5情景下增加了5.76 K。永昌站RCP4.5情景下气温距历史平均增加了2.85 K,RCP8.5情景下增加了5.01 K。乌鞘岭站RCP4.5情景下气温距历史平均增加了2.73 K,RCP8.5情景下增加了4.69 K。武威和永昌的土地类型都是以草地为主,增温幅度也较为接近,RCP4.5情景下增温约为2.9 K,RCP8.5情景下增温约为5.0 K。民勤土地类型为荒漠,RCP4.5和RCP8.5增幅幅度均大于草地。乌鞘岭属于山区增温幅度小于草地。
未来降水呈现增加趋势,在2060年之前RCP8.5和RCP4.5情景降水增加趋势较为接近,在2060—2100年RCP8.5情景降水增加明显高于RCP4.5情景(图6 B、D、F、H)。降水增加情况本研究选择2091—2100年平均与历史期1960—2005年平均比较。武威站RCP4.5情景下年降水量趋势为43 mm,RCP8.5情景下趋势为75 mm。民勤站RCP4.5情景下降水趋势为31 mm,RCP8.5情景下趋势为58 mm。永昌站RCP4.5情景下降水趋势为61 mm,RCP8.5情景下趋势为105 mm。乌鞘岭站RCP4.5情景下降水趋势为127 mm,RCP8.5情景下趋势为211 mm。武威站RCP4.5情景下降水增加率为26.7%,RCP8.5情景下降水增加率为46.4%。民勤站RCP4.5情景下降水增加率为30.3%,RCP8.5情景下降水增加率为55.3%。永昌站RCP4.5情景下降水增加率为30.3%,RCP8.5情景下降水增加率为52.5%。乌鞘岭站RCP4.5情景下降水增加率为32.4%,RCP8.5情景下降水增加率为53.7%。民勤站的降水变化比率差最大,说明荒漠下垫面降水对人为排放的影响更为敏感。
本研究4个站点可以代表3种下垫面,在不同情景下不同土地类型气温和降水增加有所不同。RCP4.5和RCP8.5情景下气温的增量排序是一致的,荒漠>草地>山地;降水的增量排序也是一致的,山地>草地>荒漠。对于降水的趋势研究,变化比率是重要的一部分,RCP4.5情景下降水增加比率山地>荒漠>草地,RCP8.5情景下降水增加比率荒漠>山地>草地。其中RCP8.5情景下荒漠降水增加比率最高(历史降水偏少,降水增加55.3%),说明RCP8.5情景下荒漠下垫面降水对全球变暖响应最为明显。
4 讨论
本研究在石羊河流域4个站点分别进行气温和降水的降尺度研究,经过对比筛选,分别给气温和降水挑选了表现良好的模型作为降尺度的模拟模型。新研究显示,筛选的多模型平均在气温和降水的降尺度上都有较好的结果,但在4个站点之间模型精度存在一定的差异性。
4.1 站点结果准确性对比
气温降尺度研究中,检验期多模型平均结果精度较好,获得与其他研究可比或更优的模拟能力。如潘小多等[32 ] 在黑河研究气温降尺度相关系数大于0.96,本研究的多模型平均相关系数大于0.98。
降水降尺度研究中,多模型平均相较于RCM模式本身和传统统计降尺度模型有着较大的精度提升。在周围其他研究区,有较多学者做过降尺度研究。如Yang等[33 ] 在黑河流域的降水降尺度研究结果,在高海拔的朱陇关村月尺度降水相关系数达到0.825,本文同为高海拔的乌鞘岭站月尺度降水结果相关系数达到0.841。又如Su等[34 ] 在黑河流域的年尺度降水降尺度研究结果,在民勤站RMSE为27.34、MAE为22.02,在永昌站RMSE为40.84、MAE为32.99。本研究有同样的站点,年尺度结果为:在民勤站RMSE为30.94、MAE为22.53,在永昌站RMSE为37.48、MAE为24.65。本研究在永昌站、乌鞘岭站模拟结果较好,在民勤站模拟结果稍差。
4.2 降水结果差异较大原因
在气温降尺度研究中,4个站点的结果精度较为接近,相关系数均在0.98以上。在降水降尺度研究中,4个站点结果精度差异较大,如武威相关系数为0.691,乌鞘岭相关系数为0.841。统计降尺度可以降低空间分辨率,并能在一定程度上订正结果误差,本研究统计降尺度的降水结果对85%降水以上的降水较多月份模拟较差。究其原因,可能是选取的CORDEX-EA模式本身在西北复杂地区的模拟结果不够理想,一些研究者研究发现CMIP5模式集合在中国西北的降水模拟较差[35 -36 ] 。而4站点降水模拟差别较大,可能原因是在西北荒漠地区CMIP5模式集合的模拟较差,气候模式很难构建荒漠区域的参数化方案。另一方面荒漠地区降水整体偏少,统计降尺度模型无法很好地建立降水与其他预测变量的关系,所以在荒漠地区降水模拟较差。统计降尺度结果在一定程度上依赖输入的模式数据,输入模型数据的不确定性是降尺度结果误差的来源之一[4 ] 。
4.3 未来气候变化
本研究选取的4个站点可以代表山地、草地、荒漠3种下垫面,乌鞘岭站代表山地,民勤站代表荒漠,永昌和武威站代表草地。未来不同气候情景下,不同下垫面气温和降水的增加存在一定规律,气温增加幅度为荒漠>草地>山地,降水增加量为山地>草地>荒漠。这说明在未来气温较高的荒漠区气温会更高,与其他两种下垫面的差异会更大;同样未来山地的降水量会更大,但草地和荒漠的降雨量也会更大。全球典型干旱半干旱区未来会出现干愈干、湿愈湿的特征,但是中国西北地区会出现气温升高降水增多较为明显的情况[37 ] 。本研究结果表明未来中国西北的荒漠地区会出现气温升高、降水增加较为明显的情况,其中气温升高更为明显;山区同样出现气温升高降水增多的情况,其中降水增多更为明显。这说明未来中国西北地区将会出现暖湿化的现象,尤其在RCP8.5时更为明显。未来西北地区的极端天气发生的频率将会更高,其中荒漠地区的极端高温和高寒山区的极端降水更值得大家关注。
4.4 机器学习模型相比于传统模型的优势
统计降尺度模型的核心是在训练期建立传递关系,再将传递关系应用到未来时期,机器学习模型可以更好地模拟这种传递关系。传统统计降尺度模型构建的传递函数,更多的是线性函数,对于训练期数据间有效信息的提取能力是有限的。机器学习模型相比于传统模型具有更好的学习能力,更善于捕捉训练期数据间的关系。卷积长短时记忆网络既具有卷积神经网络的自动特征选择功能,又具有循环神经网络的记忆功能。ELM模型为单个隐藏层前馈神经网络,模型结构简单,训练速度快,不需要复杂的参数选择就能快速学习数据的内部规律。Li等[26 ] 对加拿大安大略省气温进行降尺度研究,Alizamir等[29 ] 对伊朗降水进行降尺度研究,有着相似的发现。
4.5 机器学习模型模拟中需注意的问题
在训练模型时,机器学习模型容易出现过拟合问题,这会导致对未来的气候变化趋势的模拟失效[38 -39 ] 。机器学习模型在学习的过程中,如果训练数据中的所有条件都匹配,其中会包括噪声数据,就会得到泛化能力低的模型,导致过拟合[40 ] 。在调整机器学习模型参数中发现,模型参数对结果影响较大(如神经元个数,计算叠代次数等)。当模型参数调整到一定范围时,检验期精度可以到达较好水平(即调整参数对精度影响较小,如相关系数变化在0.001量级)。但是参数在这个范围里变化,对未来气候趋势影响较大。这主要是参数的调整使机器学习模型出现了过拟合现象,使未来气候趋势波动较大,不符合原始输入数据的变化趋势。所以在参数调整时不能只关注检验期精度,同时应关注未来气候趋势是否符合原始输入数据。
5 结论
机器学习模型相比于传统模型具有更好的学习能力,能够抓住数据中的非线性关系,统计降尺度结果有更高的精度。
不同模型在降尺度研究中的拟合能力不同,往往会引入不同的系统偏差。在经过筛选后多模型平均,可以有效地弥补这一偏差,使结果趋于稳定的状态(在不同站点最优模型往往不同,多模型平均弥补不同站点模型选择的问题,以便于增加模型的适用性)。
石羊河流域在RCP4.5情景下到2100年年均气温增加2.91 K,年降水量增加66 mm。RCP8.5情景下到2100年年均气温增加5.10 K,年降水量增加112 mm。
参考文献
View Option
[1]
Pan X Li X Cheng G et al Development and evaluation of a river-basin-scale high spatio-temporal precipitation data set using the WRF model:a case study of the Heihe River Basin
[J].Remote Sensing ,2015 ,7 (7 ):9230 -9252 .
[本文引用: 1]
[2]
徐忠峰 ,韩瑛 ,杨宗良 区域气候动力降尺度方法研究综述
[J].中国科学:地球科学 ,2019 ,49 (3 ):487 -498 .
[本文引用: 2]
[3]
范丽军 ,符淙斌 ,陈德亮 统计降尺度法对未来区域气候变化情景预估的研究进展
[J].地球科学进展 ,2005 (3 ):320 -329 .
[本文引用: 2]
[4]
张明月 ,彭定志 ,胡林涓 统计降尺度方法研究进展综述
[J].南水北调与水利科技 ,2013 ,11 (3 ):118 -122 .
[本文引用: 2]
[5]
Lee T Singh V P Statistical Downscaling for Hydrological and Environmental Applications [M].Boca Raton,USA :CRC Press ,2018 .
[本文引用: 2]
[6]
韩振宇 ,童尧 ,高学杰 ,等 分位数映射法在RegCM4中国气温模拟订正中的应用
[J].气候变化研究进展 ,2018 ,14 (4 ):331 -340 .
[本文引用: 2]
[7]
Yang Y Tang J Xiong Z et al An intercomparison of multiple statistical downscaling methods for daily precipitation and temperature over China:present climate evaluations
[J].Climate Dynamics ,2019 ,53 (7/8 ):4629 -4649 .
[本文引用: 4]
[8]
Quan T A Kenji T Coupling dynamical and statistical downscaling for high-resolution rainfall forecasting:case study of the Red River Delta,Vietnam
[J].Progress in Earth and Planetary Science ,2018 ,5 (1 ):28 .
[本文引用: 1]
[9]
Jing W Yang Y Yue X et al A comparison of different regression algorithms for downscaling monthly satellite-based precipitation over north China
[J].Remote Sensing ,2016 ,8 (10 ):835 .
[本文引用: 1]
[10]
Wang B Zheng L Liu D L et al Using multi-model ensembles of CMIP5 global climate models to reproduce observed monthly rainfall and temperature with machine learning methods in Australia
[J].International Journal of Climatology ,2018 ,38 (13 ):4891 -4902 .
[本文引用: 1]
[11]
夏德锋 ,易善桢 ,谢文豪 ,等 基于WGEN天气发生器的石羊河流域降水模拟
[J].水电能源科学 ,2020 ,38 (5 ):1 -5 .
[本文引用: 1]
[12]
李晓玲 石羊河流域气候对全球变暖的响应特征
[J].甘肃科技纵横 ,2017 ,46 (11 ):28 -32 .
[本文引用: 2]
[13]
尚海洋 ,张志强 石羊河流域土地利用类型变化与转换效果分析
[J].资源开发与市场 ,2015 ,31 (1 ):40 -43 .
[本文引用: 2]
[14]
Giorgi F Jones C Asrar G R Addressing climate information needs at the regional level:the CORDEX framework
[J].WMO Bulletin ,2009 ,53 (3 ):10 .
[本文引用: 1]
[15]
Taylor K E Stouffer R J Meehl G A An overview of CMIP 5 and the experiment design
[J].Bulletin of the American Meteorological Society ,2012 ,93 (4 ):485 -498 .
[本文引用: 1]
[16]
Zou L Zhou T A regional ocean-atmosphere coupled model developed for CORDEX East Asia:assessment of Asian summer monsoon simulation
[J].Climate Dynamics ,2016 ,47 (12 ):3627 -3640 .
[本文引用: 1]
[17]
Thomson A M Calvin K V Smith S J et al RCP4.5:a pathway for stabilization of radiative forcing by 2100
[J].Climatic Change ,2011 ,109 (1/2 ):77 -94 .
[本文引用: 1]
[18]
Riahi K Rao S Krey V et al RCP 8.5:a scenario of comparatively high greenhouse gas emissions
[J].Climatic Change ,2011 ,109 (1/2 ):33 -57 .
[本文引用: 1]
[19]
Gebrechorkos S H Hülsmann S Bernhofer C Statistically downscaled climate dataset for East Africa
[J].Scientific Data ,2019 ,6 (1 ):31 .
[本文引用: 4]
[20]
Cannon A J Sobie S R Murdock T Q Bias correction of GCM precipitation by quantile mapping:how well do methods preserve changes in quantiles and extremes?
[J].Journal of Climate ,2015 ,28 (17 ):6938 -6959 .
[本文引用: 1]
[21]
Wuthiwongyothin S Mili S Phadungkarnlert N A study of correcting climate model daily rainfall product using quantile mapping in upper Ping River Basin,Thailand
[M]//Nguyen T V,Dou X P,Tran T T.APAC 2019 .Singapore :Springer ,2020 :1213 -1219 .
[本文引用: 1]
[22]
Volosciuk C Maraun D Vrac M et al A combined statistical bias correction and stochastic downscaling method for precipitation
[J].Hydrology and Earth System Sciences ,2017 ,21 (3 ):1693 -1719 .
[本文引用: 2]
[23]
童尧 ,高学杰 ,韩振宇 ,等 基于RegCM4模式的中国区域日尺度降水模拟误差订正
[J].大气科学 ,2017 ,41 (6 ):1156 -1166 .
[本文引用: 2]
[24]
马轩龙 ,李春娥 ,陈全功 基于GIS的气象要素空间插值方法研究
[J].草业科学 ,2008 (11 ):13 -19 .
[本文引用: 1]
[25]
王亚男 ,智协飞 多模式降水集合预报的统计降尺度研究
[J].暴雨灾害 ,2012 ,31 (1 ):1 -7 .
[本文引用: 1]
[26]
Li X Li Z Huang W et al Performance of statistical and machine learning ensembles for daily temperature downscaling
[J].Theoretical and Applied Climatology ,2020 ,140 (1/2 ):571 -588 .
[本文引用: 3]
[27]
Xu L Chen N Zhang X et al Improving the North American multi-model ensemble (NMME) precipitation forecasts at local areas using wavelet and machine learning
[J].Climate Dynamics ,2019 ,53 (1/2 ):601 -615 .
[本文引用: 1]
[28]
王同亮 ,马绍休 ,高扬 ,等 小波包分解与多个机器学习模型耦合在风速预报中的对比
[J].中国沙漠 ,2021 ,41 (2 ):38 -50 .
[本文引用: 1]
[29]
Alizamir M Moghadam A M Monfared H A et al Statistical downscaling of global climate model outputs to monthly precipitation via extreme learning machine:a case study
[J].Environmental Progress & Sustainable Energy ,2018 ,37 (5 ):1853 -1862 .
[本文引用: 2]
[30]
Shi X,Gao Z,Lausen L, et al arXiv1706 .03458,2017.
[本文引用: 2]
[31]
Shi X Chen Z Wang H et al Convolutional LSTM network:a machine learning approach for precipitation nowcasting
[J].arXiv ,2015 .
[本文引用: 3]
[32]
潘小多 ,马瀚青 2000—2016年基于WRF模式的0
.05°× 0 .05°黑河流域近地表大气驱动数据[J].高原气象,2019,38 (1 ):206 -216 .
[本文引用: 1]
[33]
Yang Y Tang J Xiong Z et al Evaluation of high-resolution gridded precipitation data in arid and semiarid regions:Heihe River Basin,Northwest China
[J].Journal of Hydrometeorology ,2017 ,18 (12 ):3075 -3101 .
[本文引用: 1]
[34]
Su H Xiong Z Yan X et al An evaluation of two statistical downscaling models for downscaling monthly precipitation in the Heihe River basin of China
[J].Theoretical and Applied Climatology ,2019 ,138 (3/4 ):1913 -1923 .
[本文引用: 1]
[35]
吴晶 ,王宝鉴 ,杨艳芬 ,等 CMIP3与CMIP5模式对中国西北干旱区气温和降水的模拟能力比较
[J].气候变化研究进展 ,2017 ,13 (3 ):198 -212 .
[本文引用: 1]
[36]
陈晓晨 ,徐影 ,许崇海 ,等 CMIP5全球气候模式对中国地区降水模拟能力的评估
[J].气候变化研究进展 ,2014 ,10 (3 ):217 -225 .
[本文引用: 1]
[37]
赵天保 ,陈亮 ,马柱国 CMIP5多模式对全球典型干旱半干旱区气候变化的模拟与预估
[J].科学通报 ,2014 ,59 (12 ):1148 -1163 .
[本文引用: 1]
[38]
Wang F Tian D Lowe L et al Deep learning for daily precipitation and temperature downscaling
[J].Water Resources Research ,2021 ,57 (4 ):29308 .
[本文引用: 1]
[39]
Osman Y Z Abdellatif M E Improving accuracy of downscaling rainfall by combining predictions of different statistical downscale models
[J].Water Science ,2016 ,30 (2 ):61 -75 .
[本文引用: 1]
[40]
Bu C Zhang Z Research on overfitting problem and correction in machine learning
[J].Journal of Physics:Conference Series ,2020 ,1693 (1 ):12100 .
[本文引用: 1]
Development and evaluation of a river-basin-scale high spatio-temporal precipitation data set using the WRF model:a case study of the Heihe River Basin
1
2015
... 动力降尺度是较为常见的降尺度方法,应用广泛,但动力降尺度也有着明显的缺点[1 ] .动力降尺度使用全球气候模式的结果作为初始场和边界条件,在次网格尺度响应区域信息,从而增强大气环流的细节,达到降尺度的目的[2 ] .动力降尺度的优势是:有明确的物理意义,物理过程与现实能保持较好的一致性,并且能捕捉极端事件[2 ] .但缺点是需要较大的计算资源,模型不容易转移到新的区域,并且复杂地形下垫面参数(如海拔、土地利用等)的精度影响动力降尺度模型[3 ] . ...
区域气候动力降尺度方法研究综述
2
2019
... 动力降尺度是较为常见的降尺度方法,应用广泛,但动力降尺度也有着明显的缺点[1 ] .动力降尺度使用全球气候模式的结果作为初始场和边界条件,在次网格尺度响应区域信息,从而增强大气环流的细节,达到降尺度的目的[2 ] .动力降尺度的优势是:有明确的物理意义,物理过程与现实能保持较好的一致性,并且能捕捉极端事件[2 ] .但缺点是需要较大的计算资源,模型不容易转移到新的区域,并且复杂地形下垫面参数(如海拔、土地利用等)的精度影响动力降尺度模型[3 ] . ...
... [2 ].但缺点是需要较大的计算资源,模型不容易转移到新的区域,并且复杂地形下垫面参数(如海拔、土地利用等)的精度影响动力降尺度模型[3 ] . ...
统计降尺度法对未来区域气候变化情景预估的研究进展
2
2005
... 动力降尺度是较为常见的降尺度方法,应用广泛,但动力降尺度也有着明显的缺点[1 ] .动力降尺度使用全球气候模式的结果作为初始场和边界条件,在次网格尺度响应区域信息,从而增强大气环流的细节,达到降尺度的目的[2 ] .动力降尺度的优势是:有明确的物理意义,物理过程与现实能保持较好的一致性,并且能捕捉极端事件[2 ] .但缺点是需要较大的计算资源,模型不容易转移到新的区域,并且复杂地形下垫面参数(如海拔、土地利用等)的精度影响动力降尺度模型[3 ] . ...
... 统计降尺度作为另一种较为常见的降尺度方法,虽然无法很好体现其物理过程和机制,但是计算效率较高,模型不受地区限制,同时可以输出气候模式无法输出的变量,适用于复杂地形条件下的小区域降尺度研究.统计降尺度主要分为3类:传递函数法,天气分类法,随机天气发生器[3 ] . 其中传递函数法是较为常见的空间降尺度方法,通过建立历史观测资料和气候模式输出要素间的统计关系,并通过独立的检验期验证,再将这种关系应用于气候模式输出的未来气候要素,预估出关心区域的未来气候变化情景[4 ] ,以达到订正模式数据并降尺度的目的.常见的统计降尺度方法有Delta[5 ] 、Quantile Mapping[6 ] 、Bias-Correction and Spatial Downscaling[7 ] 、Bias-Correction and Climate Imprint[7 ] 、Bias Correction Constructed Analogues with Quantile Mapping Reordering[7 ] 等. ...
统计降尺度方法研究进展综述
2
2013
... 统计降尺度作为另一种较为常见的降尺度方法,虽然无法很好体现其物理过程和机制,但是计算效率较高,模型不受地区限制,同时可以输出气候模式无法输出的变量,适用于复杂地形条件下的小区域降尺度研究.统计降尺度主要分为3类:传递函数法,天气分类法,随机天气发生器[3 ] . 其中传递函数法是较为常见的空间降尺度方法,通过建立历史观测资料和气候模式输出要素间的统计关系,并通过独立的检验期验证,再将这种关系应用于气候模式输出的未来气候要素,预估出关心区域的未来气候变化情景[4 ] ,以达到订正模式数据并降尺度的目的.常见的统计降尺度方法有Delta[5 ] 、Quantile Mapping[6 ] 、Bias-Correction and Spatial Downscaling[7 ] 、Bias-Correction and Climate Imprint[7 ] 、Bias Correction Constructed Analogues with Quantile Mapping Reordering[7 ] 等. ...
... 在气温降尺度研究中,4个站点的结果精度较为接近,相关系数均在0.98以上.在降水降尺度研究中,4个站点结果精度差异较大,如武威相关系数为0.691,乌鞘岭相关系数为0.841.统计降尺度可以降低空间分辨率,并能在一定程度上订正结果误差,本研究统计降尺度的降水结果对85%降水以上的降水较多月份模拟较差.究其原因,可能是选取的CORDEX-EA模式本身在西北复杂地区的模拟结果不够理想,一些研究者研究发现CMIP5模式集合在中国西北的降水模拟较差[35 -36 ] .而4站点降水模拟差别较大,可能原因是在西北荒漠地区CMIP5模式集合的模拟较差,气候模式很难构建荒漠区域的参数化方案.另一方面荒漠地区降水整体偏少,统计降尺度模型无法很好地建立降水与其他预测变量的关系,所以在荒漠地区降水模拟较差.统计降尺度结果在一定程度上依赖输入的模式数据,输入模型数据的不确定性是降尺度结果误差的来源之一[4 ] . ...
2
2018
... 统计降尺度作为另一种较为常见的降尺度方法,虽然无法很好体现其物理过程和机制,但是计算效率较高,模型不受地区限制,同时可以输出气候模式无法输出的变量,适用于复杂地形条件下的小区域降尺度研究.统计降尺度主要分为3类:传递函数法,天气分类法,随机天气发生器[3 ] . 其中传递函数法是较为常见的空间降尺度方法,通过建立历史观测资料和气候模式输出要素间的统计关系,并通过独立的检验期验证,再将这种关系应用于气候模式输出的未来气候要素,预估出关心区域的未来气候变化情景[4 ] ,以达到订正模式数据并降尺度的目的.常见的统计降尺度方法有Delta[5 ] 、Quantile Mapping[6 ] 、Bias-Correction and Spatial Downscaling[7 ] 、Bias-Correction and Climate Imprint[7 ] 、Bias Correction Constructed Analogues with Quantile Mapping Reordering[7 ] 等. ...
... 分位数映射法通过匹配训练期模式数据和观测数据的概率分布函数建立传递函数,再将传递函数运用到预测期模式数据[5 -6 ,20 ] .原理是将预测期模式数据匹配到训练期观测数据的概率分布函数[21 ] ,并假设训练期的传递函数在预测期同样适用. ...
分位数映射法在RegCM4中国气温模拟订正中的应用
2
2018
... 统计降尺度作为另一种较为常见的降尺度方法,虽然无法很好体现其物理过程和机制,但是计算效率较高,模型不受地区限制,同时可以输出气候模式无法输出的变量,适用于复杂地形条件下的小区域降尺度研究.统计降尺度主要分为3类:传递函数法,天气分类法,随机天气发生器[3 ] . 其中传递函数法是较为常见的空间降尺度方法,通过建立历史观测资料和气候模式输出要素间的统计关系,并通过独立的检验期验证,再将这种关系应用于气候模式输出的未来气候要素,预估出关心区域的未来气候变化情景[4 ] ,以达到订正模式数据并降尺度的目的.常见的统计降尺度方法有Delta[5 ] 、Quantile Mapping[6 ] 、Bias-Correction and Spatial Downscaling[7 ] 、Bias-Correction and Climate Imprint[7 ] 、Bias Correction Constructed Analogues with Quantile Mapping Reordering[7 ] 等. ...
... 分位数映射法通过匹配训练期模式数据和观测数据的概率分布函数建立传递函数,再将传递函数运用到预测期模式数据[5 -6 ,20 ] .原理是将预测期模式数据匹配到训练期观测数据的概率分布函数[21 ] ,并假设训练期的传递函数在预测期同样适用. ...
An intercomparison of multiple statistical downscaling methods for daily precipitation and temperature over China:present climate evaluations
4
2019
... 统计降尺度作为另一种较为常见的降尺度方法,虽然无法很好体现其物理过程和机制,但是计算效率较高,模型不受地区限制,同时可以输出气候模式无法输出的变量,适用于复杂地形条件下的小区域降尺度研究.统计降尺度主要分为3类:传递函数法,天气分类法,随机天气发生器[3 ] . 其中传递函数法是较为常见的空间降尺度方法,通过建立历史观测资料和气候模式输出要素间的统计关系,并通过独立的检验期验证,再将这种关系应用于气候模式输出的未来气候要素,预估出关心区域的未来气候变化情景[4 ] ,以达到订正模式数据并降尺度的目的.常见的统计降尺度方法有Delta[5 ] 、Quantile Mapping[6 ] 、Bias-Correction and Spatial Downscaling[7 ] 、Bias-Correction and Climate Imprint[7 ] 、Bias Correction Constructed Analogues with Quantile Mapping Reordering[7 ] 等. ...
... [7 ]、Bias Correction Constructed Analogues with Quantile Mapping Reordering[7 ] 等. ...
... [7 ]等. ...
... 多种方法订正数据后,使用相关系数和绝对误差反映各个方法对原始数据的订正情况[7 ] . ...
Coupling dynamical and statistical downscaling for high-resolution rainfall forecasting:case study of the Red River Delta,Vietnam
1
2018
... 机器学习是被广泛应用的一种技术手段,主要用于解决分类和回归两类问题.机器学习现已被应用于大气科学领域:基于机器学习的天气气候预报技术、多源数据融合方法的发展及高分辨率气象数据的研制、数值模式与机器学习融合技术、气候事件物理机制解释、天气及气候变化的影响及辅助决策模型等.机器学习有自动捕捉空间特征的能力,这有利于复杂地形下的降尺度数据集,有很大的探索空间.机器学习模型通过计算机学习数据中的统计规律,得到线性或非线性的统计关系,再将这种统计关系应用到未来数据,以达到降尺度的目的.还有一些方法也被用到了统计降尺度中:Quan等[8 ] 使用长短时记忆网络对越南红河三角洲降水降尺度;Jing等[9 ] 使用支持向量回归和随机森林等模型对中国北方降水数据进行降尺度研究;Wang等[10 ] 使用贝叶斯回归和支持向量机对澳大利亚气温和降水进行降尺度研究. ...
A comparison of different regression algorithms for downscaling monthly satellite-based precipitation over north China
1
2016
... 机器学习是被广泛应用的一种技术手段,主要用于解决分类和回归两类问题.机器学习现已被应用于大气科学领域:基于机器学习的天气气候预报技术、多源数据融合方法的发展及高分辨率气象数据的研制、数值模式与机器学习融合技术、气候事件物理机制解释、天气及气候变化的影响及辅助决策模型等.机器学习有自动捕捉空间特征的能力,这有利于复杂地形下的降尺度数据集,有很大的探索空间.机器学习模型通过计算机学习数据中的统计规律,得到线性或非线性的统计关系,再将这种统计关系应用到未来数据,以达到降尺度的目的.还有一些方法也被用到了统计降尺度中:Quan等[8 ] 使用长短时记忆网络对越南红河三角洲降水降尺度;Jing等[9 ] 使用支持向量回归和随机森林等模型对中国北方降水数据进行降尺度研究;Wang等[10 ] 使用贝叶斯回归和支持向量机对澳大利亚气温和降水进行降尺度研究. ...
Using multi-model ensembles of CMIP5 global climate models to reproduce observed monthly rainfall and temperature with machine learning methods in Australia
1
2018
... 机器学习是被广泛应用的一种技术手段,主要用于解决分类和回归两类问题.机器学习现已被应用于大气科学领域:基于机器学习的天气气候预报技术、多源数据融合方法的发展及高分辨率气象数据的研制、数值模式与机器学习融合技术、气候事件物理机制解释、天气及气候变化的影响及辅助决策模型等.机器学习有自动捕捉空间特征的能力,这有利于复杂地形下的降尺度数据集,有很大的探索空间.机器学习模型通过计算机学习数据中的统计规律,得到线性或非线性的统计关系,再将这种统计关系应用到未来数据,以达到降尺度的目的.还有一些方法也被用到了统计降尺度中:Quan等[8 ] 使用长短时记忆网络对越南红河三角洲降水降尺度;Jing等[9 ] 使用支持向量回归和随机森林等模型对中国北方降水数据进行降尺度研究;Wang等[10 ] 使用贝叶斯回归和支持向量机对澳大利亚气温和降水进行降尺度研究. ...
基于WGEN天气发生器的石羊河流域降水模拟
1
2020
... 石羊河是甘肃省河西走廊内流水系的第三大河,是中国较为重要的内陆河.近年来由于气候变化和人类活动的影响,其生态环境及水资源合理利用的问题引起广泛关注,例如有学者基于天气发生器模拟了未来降水的变化[11 ] ,以及气候变化对石羊河流域的影响[12 -13 ] 等.但是,关于石羊河流域未来气候变化的数据以及影响研究较少.因此,本研究旨在探索简单、可靠和可操作降尺度方法,为区域气候变化研究提供基础数据. ...
石羊河流域气候对全球变暖的响应特征
2
2017
... 石羊河是甘肃省河西走廊内流水系的第三大河,是中国较为重要的内陆河.近年来由于气候变化和人类活动的影响,其生态环境及水资源合理利用的问题引起广泛关注,例如有学者基于天气发生器模拟了未来降水的变化[11 ] ,以及气候变化对石羊河流域的影响[12 -13 ] 等.但是,关于石羊河流域未来气候变化的数据以及影响研究较少.因此,本研究旨在探索简单、可靠和可操作降尺度方法,为区域气候变化研究提供基础数据. ...
... 石羊河位于甘肃省河西走廊东部,乌鞘岭以西,源于南部祁连山,消失于民勤盆地北部(36°—39°N、101°—104°E).流域内地形复杂,包括冰川、积雪、森林、沙漠、河流、城镇、耕地等多种土地类型,海拔1 247—5 128 m[13 ] ,是研究统计降尺度模型适用性的理想区域,具体信息见图1 .本研究选择流域内4个站点(武威、乌鞘岭、民勤和永昌)进行降尺度研究,站点主要信息见表1 [12 ] . ...
石羊河流域土地利用类型变化与转换效果分析
2
2015
... 石羊河是甘肃省河西走廊内流水系的第三大河,是中国较为重要的内陆河.近年来由于气候变化和人类活动的影响,其生态环境及水资源合理利用的问题引起广泛关注,例如有学者基于天气发生器模拟了未来降水的变化[11 ] ,以及气候变化对石羊河流域的影响[12 -13 ] 等.但是,关于石羊河流域未来气候变化的数据以及影响研究较少.因此,本研究旨在探索简单、可靠和可操作降尺度方法,为区域气候变化研究提供基础数据. ...
... 石羊河位于甘肃省河西走廊东部,乌鞘岭以西,源于南部祁连山,消失于民勤盆地北部(36°—39°N、101°—104°E).流域内地形复杂,包括冰川、积雪、森林、沙漠、河流、城镇、耕地等多种土地类型,海拔1 247—5 128 m[13 ] ,是研究统计降尺度模型适用性的理想区域,具体信息见图1 .本研究选择流域内4个站点(武威、乌鞘岭、民勤和永昌)进行降尺度研究,站点主要信息见表1 [12 ] . ...
Addressing climate information needs at the regional level:the CORDEX framework
1
2009
... 本研究选用HadGEM3-RA模式数据[14 ] ,数据源为韩国国家气象研究所(National Institute of Meteorological Research)(http://cordex-ea.climate.go.kr/cordex/ ).该模型是the Coupled Model Intercomparison Project Phase 5 (CMIP5)项目[15 ] 下针对东亚的区域气候产品,已广泛用于气候评估研究[16 ] .模式数据时间分辨率为1 d,空间分辨率为0.44°,本研究选择月平均数据.包括历史时期(1960—2005年)数据与RCP4.5情景[17 ] 下预测的未来时期气候模式数据(2006—2100年),RCP8.5情景[18 ] 下预测的未来时期气候模式数据(2006—2100年).本研究选取模式中8个被常用于降尺度模型的变量[19 ] (表2 ).时间分段设置:训练期为1960—1990年,检验期为1991—2005年,预测期为2006—2100年. ...
An overview of CMIP 5 and the experiment design
1
2012
... 本研究选用HadGEM3-RA模式数据[14 ] ,数据源为韩国国家气象研究所(National Institute of Meteorological Research)(http://cordex-ea.climate.go.kr/cordex/ ).该模型是the Coupled Model Intercomparison Project Phase 5 (CMIP5)项目[15 ] 下针对东亚的区域气候产品,已广泛用于气候评估研究[16 ] .模式数据时间分辨率为1 d,空间分辨率为0.44°,本研究选择月平均数据.包括历史时期(1960—2005年)数据与RCP4.5情景[17 ] 下预测的未来时期气候模式数据(2006—2100年),RCP8.5情景[18 ] 下预测的未来时期气候模式数据(2006—2100年).本研究选取模式中8个被常用于降尺度模型的变量[19 ] (表2 ).时间分段设置:训练期为1960—1990年,检验期为1991—2005年,预测期为2006—2100年. ...
A regional ocean-atmosphere coupled model developed for CORDEX East Asia:assessment of Asian summer monsoon simulation
1
2016
... 本研究选用HadGEM3-RA模式数据[14 ] ,数据源为韩国国家气象研究所(National Institute of Meteorological Research)(http://cordex-ea.climate.go.kr/cordex/ ).该模型是the Coupled Model Intercomparison Project Phase 5 (CMIP5)项目[15 ] 下针对东亚的区域气候产品,已广泛用于气候评估研究[16 ] .模式数据时间分辨率为1 d,空间分辨率为0.44°,本研究选择月平均数据.包括历史时期(1960—2005年)数据与RCP4.5情景[17 ] 下预测的未来时期气候模式数据(2006—2100年),RCP8.5情景[18 ] 下预测的未来时期气候模式数据(2006—2100年).本研究选取模式中8个被常用于降尺度模型的变量[19 ] (表2 ).时间分段设置:训练期为1960—1990年,检验期为1991—2005年,预测期为2006—2100年. ...
RCP4.5:a pathway for stabilization of radiative forcing by 2100
1
2011
... 本研究选用HadGEM3-RA模式数据[14 ] ,数据源为韩国国家气象研究所(National Institute of Meteorological Research)(http://cordex-ea.climate.go.kr/cordex/ ).该模型是the Coupled Model Intercomparison Project Phase 5 (CMIP5)项目[15 ] 下针对东亚的区域气候产品,已广泛用于气候评估研究[16 ] .模式数据时间分辨率为1 d,空间分辨率为0.44°,本研究选择月平均数据.包括历史时期(1960—2005年)数据与RCP4.5情景[17 ] 下预测的未来时期气候模式数据(2006—2100年),RCP8.5情景[18 ] 下预测的未来时期气候模式数据(2006—2100年).本研究选取模式中8个被常用于降尺度模型的变量[19 ] (表2 ).时间分段设置:训练期为1960—1990年,检验期为1991—2005年,预测期为2006—2100年. ...
RCP 8.5:a scenario of comparatively high greenhouse gas emissions
1
2011
... 本研究选用HadGEM3-RA模式数据[14 ] ,数据源为韩国国家气象研究所(National Institute of Meteorological Research)(http://cordex-ea.climate.go.kr/cordex/ ).该模型是the Coupled Model Intercomparison Project Phase 5 (CMIP5)项目[15 ] 下针对东亚的区域气候产品,已广泛用于气候评估研究[16 ] .模式数据时间分辨率为1 d,空间分辨率为0.44°,本研究选择月平均数据.包括历史时期(1960—2005年)数据与RCP4.5情景[17 ] 下预测的未来时期气候模式数据(2006—2100年),RCP8.5情景[18 ] 下预测的未来时期气候模式数据(2006—2100年).本研究选取模式中8个被常用于降尺度模型的变量[19 ] (表2 ).时间分段设置:训练期为1960—1990年,检验期为1991—2005年,预测期为2006—2100年. ...
Statistically downscaled climate dataset for East Africa
4
2019
... 本研究选用HadGEM3-RA模式数据[14 ] ,数据源为韩国国家气象研究所(National Institute of Meteorological Research)(http://cordex-ea.climate.go.kr/cordex/ ).该模型是the Coupled Model Intercomparison Project Phase 5 (CMIP5)项目[15 ] 下针对东亚的区域气候产品,已广泛用于气候评估研究[16 ] .模式数据时间分辨率为1 d,空间分辨率为0.44°,本研究选择月平均数据.包括历史时期(1960—2005年)数据与RCP4.5情景[17 ] 下预测的未来时期气候模式数据(2006—2100年),RCP8.5情景[18 ] 下预测的未来时期气候模式数据(2006—2100年).本研究选取模式中8个被常用于降尺度模型的变量[19 ] (表2 ).时间分段设置:训练期为1960—1990年,检验期为1991—2005年,预测期为2006—2100年. ...
... 本研究选择8种区域气候模式数据输出变量作为输入,以建立训练期各变量与目标(站点的气温、降水)间的线性关系.8种输入变量,根据物理关系及文献经验选取[19 ] .主要包括3个步骤: ...
... 本文使用的多元线性回归公式如下,预测因子根据大气科学的基本常识选取[19 ] : ...
... 本研究选用4种机器学习模型研究,机器学习模型的输入选择8种不同变量数据(表2 ),8种变量根据物理关系及文献经验选取[19 ] .在输入机器学习模型前进行数据标准化处理,以消除单位等量纲的影响.然后将无量纲化的数据输入机器学习模型(支持向量回归模型取最优曲线,人工神经网络模型输入多个神经元,极限学习机模型输入隐藏层再输入多个神经元,卷积长短时记忆网络模型先输入卷积层再输入长短时记忆神经网络神经元),建立检验期自变量(无量纲的8种输入变量)与目标变量(站点气温、降水)间的关系,训练机器学习模型.将未来期数据输入训练好的模型,即可得到未来站点结果. ...
Bias correction of GCM precipitation by quantile mapping:how well do methods preserve changes in quantiles and extremes?
1
2015
... 分位数映射法通过匹配训练期模式数据和观测数据的概率分布函数建立传递函数,再将传递函数运用到预测期模式数据[5 -6 ,20 ] .原理是将预测期模式数据匹配到训练期观测数据的概率分布函数[21 ] ,并假设训练期的传递函数在预测期同样适用. ...
A study of correcting climate model daily rainfall product using quantile mapping in upper Ping River Basin,Thailand
1
2020
... 分位数映射法通过匹配训练期模式数据和观测数据的概率分布函数建立传递函数,再将传递函数运用到预测期模式数据[5 -6 ,20 ] .原理是将预测期模式数据匹配到训练期观测数据的概率分布函数[21 ] ,并假设训练期的传递函数在预测期同样适用. ...
A combined statistical bias correction and stochastic downscaling method for precipitation
2
2017
... 概率分布函数在分位数映射法中用来描述模式数据和观测数据的分布方式,常见的有理论概率分布和经验累积概率分布.理论概率分布函数对极值的订正效果较差,另外如当观测和模式气温数据不满足正态分布时,订正效果会不明显[22 ] .经验累积概率分布函数中参数转换对于模式模拟的误差有较好的改善效果[23 ] ,并能够较好地描述模式数据和观测数据的分布方式.综上本研究选取经验累积概率分布函数. ...
... 传递函数在分位数映射法中用来建立训练期模式数据和观测数据的函数关系,常见的有参数函数和非参数函数.其中参数转换函数对于模式模拟的误差有较好的改善效果,例如线性函数、指数函数.非参数转换适用性更广泛,不需要对原始数据做前提假设[22 ] ,例如单调三次样条插值法、局部线性最小二乘回归法+线性插值法、三次光滑样条拟合法+广义交叉验证光滑参数法[23 ] .本研究是月尺度数据间的函数转换,所以选取较为简单的一次线性函数作为传递函数. ...
基于RegCM4模式的中国区域日尺度降水模拟误差订正
2
2017
... 概率分布函数在分位数映射法中用来描述模式数据和观测数据的分布方式,常见的有理论概率分布和经验累积概率分布.理论概率分布函数对极值的订正效果较差,另外如当观测和模式气温数据不满足正态分布时,订正效果会不明显[22 ] .经验累积概率分布函数中参数转换对于模式模拟的误差有较好的改善效果[23 ] ,并能够较好地描述模式数据和观测数据的分布方式.综上本研究选取经验累积概率分布函数. ...
... 传递函数在分位数映射法中用来建立训练期模式数据和观测数据的函数关系,常见的有参数函数和非参数函数.其中参数转换函数对于模式模拟的误差有较好的改善效果,例如线性函数、指数函数.非参数转换适用性更广泛,不需要对原始数据做前提假设[22 ] ,例如单调三次样条插值法、局部线性最小二乘回归法+线性插值法、三次光滑样条拟合法+广义交叉验证光滑参数法[23 ] .本研究是月尺度数据间的函数转换,所以选取较为简单的一次线性函数作为传递函数. ...
基于GIS的气象要素空间插值方法研究
1
2008
... 由于模式数据是网格化的,无法直接使用分位数映射法,所以本研究选用反距离权重法作为降尺度方法,将模式数据插值到站点.反距离权重法是距离倒数乘方格网化方法,是一个加权平均插值法,可以确切的或者圆滑的方式插值.方次参数控制着权重系数如何随着离开一个格网结点距离的增加而下降.对于一个较大的方次,较近的数据点被给定一个较高的权重份额,对于一个较小的方次,权重比较均匀地分配给各数据点[24 ] ,本次研究选取方次为2[25 ] . ...
多模式降水集合预报的统计降尺度研究
1
2012
... 由于模式数据是网格化的,无法直接使用分位数映射法,所以本研究选用反距离权重法作为降尺度方法,将模式数据插值到站点.反距离权重法是距离倒数乘方格网化方法,是一个加权平均插值法,可以确切的或者圆滑的方式插值.方次参数控制着权重系数如何随着离开一个格网结点距离的增加而下降.对于一个较大的方次,较近的数据点被给定一个较高的权重份额,对于一个较小的方次,权重比较均匀地分配给各数据点[24 ] ,本次研究选取方次为2[25 ] . ...
Performance of statistical and machine learning ensembles for daily temperature downscaling
3
2020
... 支持向量回归属于支持向量机,该模型主要应用于回归问题.支持向量回归的核心思想是寻找一条最佳拟合曲线,在容忍偏差范围内,曲线包含尽可能多的数据点.回归方程的数学描述为[26 ] : ...
... 支持向量回归的优化问题描述为[26 ] : ...
... 统计降尺度模型的核心是在训练期建立传递关系,再将传递关系应用到未来时期,机器学习模型可以更好地模拟这种传递关系.传统统计降尺度模型构建的传递函数,更多的是线性函数,对于训练期数据间有效信息的提取能力是有限的.机器学习模型相比于传统模型具有更好的学习能力,更善于捕捉训练期数据间的关系.卷积长短时记忆网络既具有卷积神经网络的自动特征选择功能,又具有循环神经网络的记忆功能.ELM模型为单个隐藏层前馈神经网络,模型结构简单,训练速度快,不需要复杂的参数选择就能快速学习数据的内部规律.Li等[26 ] 对加拿大安大略省气温进行降尺度研究,Alizamir等[29 ] 对伊朗降水进行降尺度研究,有着相似的发现. ...
Improving the North American multi-model ensemble (NMME) precipitation forecasts at local areas using wavelet and machine learning
1
2019
... 支持向量回归的预测可以定义为[27 ] : ...
小波包分解与多个机器学习模型耦合在风速预报中的对比
1
2021
... 人工神经网络是受人类大脑结构启发得到的,该网络由一系列相互连接的神经元构成.网络内部不同神经元之间通过权重相连,神经元内设有激活函数和偏差.根据使用的激活函数和学习算法的不同,人工神经网络可以分为不同类别.人工神经网络的数学描述为[28 ] : ...
Statistical downscaling of global climate model outputs to monthly precipitation via extreme learning machine:a case study
2
2018
... 极限学习机也属于人工神经网络,是一类包含单个隐藏层的前馈神经网络[29 ] ,该算法最大的特点是在保证学习精度的前提下训练速度更快.极限学习机在训练模型前,首先随机初始化输入权重和偏差,同时确定输出矩阵.不同于传统的神经网络,极限学习机在迭代时不需要更新全部参数,仅通过输出矩阵求解相应方程组就能快速训练模型.极限学习机的损失函数描述为: ...
... 统计降尺度模型的核心是在训练期建立传递关系,再将传递关系应用到未来时期,机器学习模型可以更好地模拟这种传递关系.传统统计降尺度模型构建的传递函数,更多的是线性函数,对于训练期数据间有效信息的提取能力是有限的.机器学习模型相比于传统模型具有更好的学习能力,更善于捕捉训练期数据间的关系.卷积长短时记忆网络既具有卷积神经网络的自动特征选择功能,又具有循环神经网络的记忆功能.ELM模型为单个隐藏层前馈神经网络,模型结构简单,训练速度快,不需要复杂的参数选择就能快速学习数据的内部规律.Li等[26 ] 对加拿大安大略省气温进行降尺度研究,Alizamir等[29 ] 对伊朗降水进行降尺度研究,有着相似的发现. ...
2
arXiv1706
... 长短时记忆网络是一种特殊的循环神经网络,用来解决长序列训练过程中的梯度消失和梯度爆炸问题.主要包括遗忘阶段、选择输入阶段、输出阶段[30 ] . ...
... 卷积长短时记忆网络不仅具有长短时记忆网络的时序建模能力[30 ] ,而且还能像卷积神经网络一样刻画局部特征[31 ] .卷积长短时记忆网络是将基础的长短时记忆网络的输入和传递过程的前馈式计算替换成卷积的形式,即输入与各个门之间的连接由前馈式替换成了卷积,同时状态与状态之间也换成了卷积运算.长短时记忆网络的输入门、遗忘门、输出门保持不变.输入门决定细胞状态中存储的信息,遗忘门决定细胞状态中被遗忘的信息,输出门决定最终输出.单个神经元的计算过程为:①输入数据,输入门激活,计算输入细胞的信息.②如果遗忘门激活,遗忘部分细胞中保留的历史状态.③输出门激活,计算神经元的输出信息,并更新细胞状态.每个神经元都包含上述3个门,在模型进行计算时,神经元内计算过程可以描述为[31 ] : ...
Convolutional LSTM network:a machine learning approach for precipitation nowcasting
3
2015
... 卷积长短时记忆网络不仅具有长短时记忆网络的时序建模能力[30 ] ,而且还能像卷积神经网络一样刻画局部特征[31 ] .卷积长短时记忆网络是将基础的长短时记忆网络的输入和传递过程的前馈式计算替换成卷积的形式,即输入与各个门之间的连接由前馈式替换成了卷积,同时状态与状态之间也换成了卷积运算.长短时记忆网络的输入门、遗忘门、输出门保持不变.输入门决定细胞状态中存储的信息,遗忘门决定细胞状态中被遗忘的信息,输出门决定最终输出.单个神经元的计算过程为:①输入数据,输入门激活,计算输入细胞的信息.②如果遗忘门激活,遗忘部分细胞中保留的历史状态.③输出门激活,计算神经元的输出信息,并更新细胞状态.每个神经元都包含上述3个门,在模型进行计算时,神经元内计算过程可以描述为[31 ] : ...
... [31 ]: ...
... 式中:x =(x 1 ,x 2 ,···,xt )为展开层数据;it 为输入门;ft 为遗忘门;Ct 为记忆细胞的激活矢量;ot 为输出门;Ht 为每个记忆块的激活矢量;W 为权重矩阵;b 为偏差矢量;∘为点积;*为卷积;σ 为激活函数,tanh 为激活函数,激活函数数学描述为[31 ] : ...
2000—2016年基于WRF模式的0
1
0
... 气温降尺度研究中,检验期多模型平均结果精度较好,获得与其他研究可比或更优的模拟能力.如潘小多等[32 ] 在黑河研究气温降尺度相关系数大于0.96,本研究的多模型平均相关系数大于0.98. ...
Evaluation of high-resolution gridded precipitation data in arid and semiarid regions:Heihe River Basin,Northwest China
1
2017
... 降水降尺度研究中,多模型平均相较于RCM模式本身和传统统计降尺度模型有着较大的精度提升.在周围其他研究区,有较多学者做过降尺度研究.如Yang等[33 ] 在黑河流域的降水降尺度研究结果,在高海拔的朱陇关村月尺度降水相关系数达到0.825,本文同为高海拔的乌鞘岭站月尺度降水结果相关系数达到0.841.又如Su等[34 ] 在黑河流域的年尺度降水降尺度研究结果,在民勤站RMSE为27.34、MAE为22.02,在永昌站RMSE为40.84、MAE为32.99.本研究有同样的站点,年尺度结果为:在民勤站RMSE为30.94、MAE为22.53,在永昌站RMSE为37.48、MAE为24.65.本研究在永昌站、乌鞘岭站模拟结果较好,在民勤站模拟结果稍差. ...
An evaluation of two statistical downscaling models for downscaling monthly precipitation in the Heihe River basin of China
1
2019
... 降水降尺度研究中,多模型平均相较于RCM模式本身和传统统计降尺度模型有着较大的精度提升.在周围其他研究区,有较多学者做过降尺度研究.如Yang等[33 ] 在黑河流域的降水降尺度研究结果,在高海拔的朱陇关村月尺度降水相关系数达到0.825,本文同为高海拔的乌鞘岭站月尺度降水结果相关系数达到0.841.又如Su等[34 ] 在黑河流域的年尺度降水降尺度研究结果,在民勤站RMSE为27.34、MAE为22.02,在永昌站RMSE为40.84、MAE为32.99.本研究有同样的站点,年尺度结果为:在民勤站RMSE为30.94、MAE为22.53,在永昌站RMSE为37.48、MAE为24.65.本研究在永昌站、乌鞘岭站模拟结果较好,在民勤站模拟结果稍差. ...
CMIP3与CMIP5模式对中国西北干旱区气温和降水的模拟能力比较
1
2017
... 在气温降尺度研究中,4个站点的结果精度较为接近,相关系数均在0.98以上.在降水降尺度研究中,4个站点结果精度差异较大,如武威相关系数为0.691,乌鞘岭相关系数为0.841.统计降尺度可以降低空间分辨率,并能在一定程度上订正结果误差,本研究统计降尺度的降水结果对85%降水以上的降水较多月份模拟较差.究其原因,可能是选取的CORDEX-EA模式本身在西北复杂地区的模拟结果不够理想,一些研究者研究发现CMIP5模式集合在中国西北的降水模拟较差[35 -36 ] .而4站点降水模拟差别较大,可能原因是在西北荒漠地区CMIP5模式集合的模拟较差,气候模式很难构建荒漠区域的参数化方案.另一方面荒漠地区降水整体偏少,统计降尺度模型无法很好地建立降水与其他预测变量的关系,所以在荒漠地区降水模拟较差.统计降尺度结果在一定程度上依赖输入的模式数据,输入模型数据的不确定性是降尺度结果误差的来源之一[4 ] . ...
CMIP5全球气候模式对中国地区降水模拟能力的评估
1
2014
... 在气温降尺度研究中,4个站点的结果精度较为接近,相关系数均在0.98以上.在降水降尺度研究中,4个站点结果精度差异较大,如武威相关系数为0.691,乌鞘岭相关系数为0.841.统计降尺度可以降低空间分辨率,并能在一定程度上订正结果误差,本研究统计降尺度的降水结果对85%降水以上的降水较多月份模拟较差.究其原因,可能是选取的CORDEX-EA模式本身在西北复杂地区的模拟结果不够理想,一些研究者研究发现CMIP5模式集合在中国西北的降水模拟较差[35 -36 ] .而4站点降水模拟差别较大,可能原因是在西北荒漠地区CMIP5模式集合的模拟较差,气候模式很难构建荒漠区域的参数化方案.另一方面荒漠地区降水整体偏少,统计降尺度模型无法很好地建立降水与其他预测变量的关系,所以在荒漠地区降水模拟较差.统计降尺度结果在一定程度上依赖输入的模式数据,输入模型数据的不确定性是降尺度结果误差的来源之一[4 ] . ...
CMIP5多模式对全球典型干旱半干旱区气候变化的模拟与预估
1
2014
... 本研究选取的4个站点可以代表山地、草地、荒漠3种下垫面,乌鞘岭站代表山地,民勤站代表荒漠,永昌和武威站代表草地.未来不同气候情景下,不同下垫面气温和降水的增加存在一定规律,气温增加幅度为荒漠>草地>山地,降水增加量为山地>草地>荒漠.这说明在未来气温较高的荒漠区气温会更高,与其他两种下垫面的差异会更大;同样未来山地的降水量会更大,但草地和荒漠的降雨量也会更大.全球典型干旱半干旱区未来会出现干愈干、湿愈湿的特征,但是中国西北地区会出现气温升高降水增多较为明显的情况[37 ] .本研究结果表明未来中国西北的荒漠地区会出现气温升高、降水增加较为明显的情况,其中气温升高更为明显;山区同样出现气温升高降水增多的情况,其中降水增多更为明显.这说明未来中国西北地区将会出现暖湿化的现象,尤其在RCP8.5时更为明显.未来西北地区的极端天气发生的频率将会更高,其中荒漠地区的极端高温和高寒山区的极端降水更值得大家关注. ...
Deep learning for daily precipitation and temperature downscaling
1
2021
... 在训练模型时,机器学习模型容易出现过拟合问题,这会导致对未来的气候变化趋势的模拟失效[38 -39 ] .机器学习模型在学习的过程中,如果训练数据中的所有条件都匹配,其中会包括噪声数据,就会得到泛化能力低的模型,导致过拟合[40 ] .在调整机器学习模型参数中发现,模型参数对结果影响较大(如神经元个数,计算叠代次数等).当模型参数调整到一定范围时,检验期精度可以到达较好水平(即调整参数对精度影响较小,如相关系数变化在0.001量级).但是参数在这个范围里变化,对未来气候趋势影响较大.这主要是参数的调整使机器学习模型出现了过拟合现象,使未来气候趋势波动较大,不符合原始输入数据的变化趋势.所以在参数调整时不能只关注检验期精度,同时应关注未来气候趋势是否符合原始输入数据. ...
Improving accuracy of downscaling rainfall by combining predictions of different statistical downscale models
1
2016
... 在训练模型时,机器学习模型容易出现过拟合问题,这会导致对未来的气候变化趋势的模拟失效[38 -39 ] .机器学习模型在学习的过程中,如果训练数据中的所有条件都匹配,其中会包括噪声数据,就会得到泛化能力低的模型,导致过拟合[40 ] .在调整机器学习模型参数中发现,模型参数对结果影响较大(如神经元个数,计算叠代次数等).当模型参数调整到一定范围时,检验期精度可以到达较好水平(即调整参数对精度影响较小,如相关系数变化在0.001量级).但是参数在这个范围里变化,对未来气候趋势影响较大.这主要是参数的调整使机器学习模型出现了过拟合现象,使未来气候趋势波动较大,不符合原始输入数据的变化趋势.所以在参数调整时不能只关注检验期精度,同时应关注未来气候趋势是否符合原始输入数据. ...
Research on overfitting problem and correction in machine learning
1
2020
... 在训练模型时,机器学习模型容易出现过拟合问题,这会导致对未来的气候变化趋势的模拟失效[38 -39 ] .机器学习模型在学习的过程中,如果训练数据中的所有条件都匹配,其中会包括噪声数据,就会得到泛化能力低的模型,导致过拟合[40 ] .在调整机器学习模型参数中发现,模型参数对结果影响较大(如神经元个数,计算叠代次数等).当模型参数调整到一定范围时,检验期精度可以到达较好水平(即调整参数对精度影响较小,如相关系数变化在0.001量级).但是参数在这个范围里变化,对未来气候趋势影响较大.这主要是参数的调整使机器学习模型出现了过拟合现象,使未来气候趋势波动较大,不符合原始输入数据的变化趋势.所以在参数调整时不能只关注检验期精度,同时应关注未来气候趋势是否符合原始输入数据. ...




 甘公网安备 62010202000688号
甘公网安备 62010202000688号
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}