


0 引言
风沙跃移是半干旱和干旱地表的关键地球物理过程,是沙丘、戈壁和雅丹等地貌演变的主要驱动力[1]。跃移轨迹演化是理解跃移过程的重要窗口,过去20多年来研究人员利用数字高速摄影技术及风沙颗粒轨迹追踪算法(Saltating particle tracking,SPT)对此开展了深入的研究,并取得了一系列重要的进展,如发现了起跳速度的单峰和双峰分布[2-3]、恢复了跃移运动参数[4]、重构了侧向速度分量[5-7]、证实了颗粒流粒载切应力廓线[5-6,8],发展了各类的跃移尺度律[9-12]。然而目前发展的SPT算法的性能还有待于进一步提高。具体地说,我们最近提出的混合卡尔曼滤波-匈牙利算法(KF-H-k)[13],虽然性能强于以前的算法,但在中等颗粒浓度(每帧103~134个颗粒)下,为了保证轨迹正确率,KF-H-k去除了大量有效颗粒位置,其召回率仅为50%~60%。这意味着目前的SPT算法还难以满足风沙颗粒追踪的需求,因而发展新的SPT算法势在必行。新算法的发展首先遇到的瓶颈是需要借助人工识别的方法来评价算法的性能,而这非常耗时,因而在新算法发展过程中,迫切地需要发展风沙轨迹自动识别的方法,以提高算法评价的效率。
跃移轨迹的自动识别属于二分类问题,因而利用上述集成学习模型来解决此问题是可行的,但是作为数据驱动的模型,其性能还依赖于训练数据集的特征,因而构建合适的跃移轨迹数据集也同样重要。鉴于此,本文基于我们团队提出的SPT算法[13],构建了包括正确和错误轨迹的数据集,以发展优化的集成学习模型并进而实现对风沙轨迹的自动识别,以期为构建基于机器学习的沙粒追踪算法奠定基础。
1 研究方法
1.1 跃移轨迹数据来源
跃移轨迹数据来自在陕西师范大学风沙过程动力学风洞实验室拍摄的高速视频。该视频的拍摄频率为3 000 Hz,空间分辨率为39.4 mm×29.5 mm,共57 652帧。
这里分别采用最近邻算法[13]、匈牙利算法[13]、卡尔曼滤波-匈牙利算法[13](KF-H)及混合卡尔曼滤波-匈牙利算法[13](KF-H-k)对来自于极低浓度E(4个颗粒·帧-1)、低浓度L1(26个颗粒·帧-1)、低浓度L2(30个颗粒·帧-1)、低浓度L3(35个颗粒·帧-1)、中浓度M1(103个颗粒·帧-1)、中浓度M2(108个颗粒·帧-1)和中浓度M3(134个颗粒·帧-1)等7段视频进行追踪,共提取了7 564条轨迹,并且这些轨迹的长度(轨迹中所包含的颗粒位置数量)均在3~110。原始轨迹数据包括了轨迹的序号,轨迹的横、纵坐标(单位为像素)以及帧号,图1展示了由KF-H-k算法提取的原始轨迹数据所绘制的视频M1下的跃移轨迹汇总图。最后,通过与对应帧原始图像中的跃移颗粒位置对比,当算法恢复轨迹中的所有位置与真实位置一一对应时,即将这条轨迹标记为正确轨迹,否则标记为错误轨迹。
图1
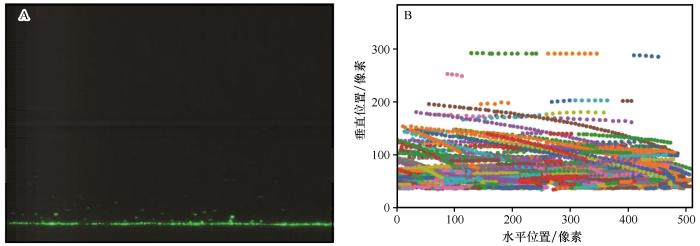
图1
M1视频的第23帧图片(A),由KF-H-k算法提取的视频M1中的跃移颗粒轨迹(B)
Fig.1
The 23rd frame of the M1 section (A), the recovered saltating tracks from the M1 section via the KF-H-k (B)
1.2 跃移轨迹数据的参数化方案
为了刻画跃移轨迹的特征,这里选用了跃移轨迹的瞬时水平速度、垂直速度、合速度等变量(表1)并以这3个变量的均值刻画跃移轨迹,即表1中的变量
表1 跃移轨迹数据集的参数化特征
Table 1
| 变量 | 定义 |
|---|---|
| 瞬时水平速度的平均值(m·s-1) | |
| 瞬时垂直速度的平均值(m·s-1) | |
| 瞬时合速度的平均值(m·s-1) | |
| 轨迹抛物线方程拟合曲线的决定系数, |
图2
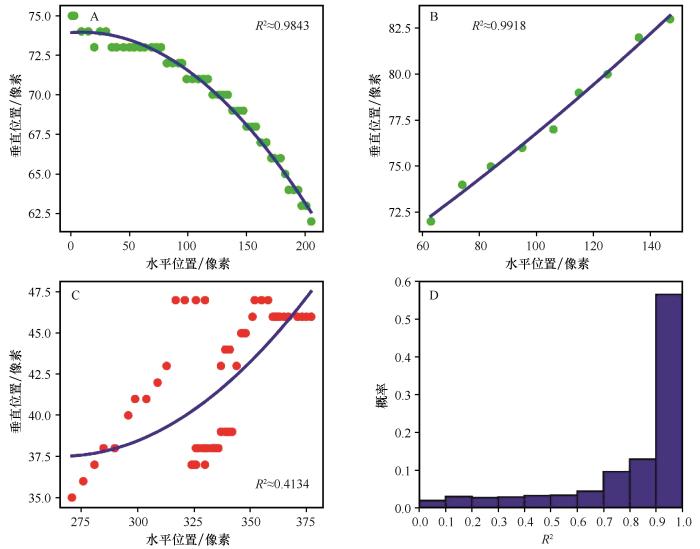
图2
由KF-H算法提取视频M1中的第27号正确的上升轨迹(A),第7号正确的下降轨迹(B)和第16号错误轨迹(C)以及5 756条正确轨迹的拟合二次曲线的决定系数(R2 )的概率分布(D)
Fig.2
The 27th true ascent trajectory (A), the 7th true descent trajectory (B) and the 16th false trajectory (C)in video M1 extracted by the KF-H algorithm, respectively; Probability distribution of the determination coefficient (R2 ) for fitting quadratic curves of 5 756 true trajectories (D)
1.3 集成学习模型及训练流程
本研究采用了4种集成学习模型,包括随机森林(Random Forest)、极度随机树(Extremely Randomized Trees)、梯度提升决策树(Gradient Boosting Decision Tree)和XGBoost。随机森林使用自举法(bootstrap)通过从原始数据集中有放回地随机抽取样本,形成多个子训练集,然后利用这些子训练集来训练多个基础学习器,最终采用投票的方式得到预测结果。极度随机树基于未剪枝回归树或决策树构建算法。与随机森林不同,极度随机树在训练模型时不采用自举法而是使用整个数据集进行节点划分及优化。梯度提升决策树是基于boosting算法的机器学习方法,通过不断强化弱学习器来获得强学习器,其在每次迭代中调整每一棵决策树,以最小化输出的预测值与真实标签之间的损失,进而逐步提升整体模型的预测能力。XGBoost在梯度提升决策树的基础上做了大量改进,包括加入了模型的正则项、改进了损失函数、采取了权重收缩和子采样等策略。此外,XGBoost还增加了Column Block、Cache-aware Access和Blocks for Out-of-core Computation等技术,进一步缩短了训练时间。
图3
表2 通过Tree-structured Parzen Estimator优化后的各个模型的最终超参数设置
Table 2
| 算法 | HP1 | HP2 | HP3 | HP4 | HP5 | HP6 | HP7 | HP8 | HP9 | HP10 |
|---|---|---|---|---|---|---|---|---|---|---|
| 随机森林 | True | -1 | True | 180 | 18 | True | “sqrt” | “gini” | ||
| 梯度提升决策树 | True | -1 | True | 210 | 3 | 0.3 | ||||
| XGBoost | True | -1 | 70 | 6 | 0.3 | 0.5 | ||||
| 极度随机树 | True | -1 | True | 186 | 21 | 0.1 | True | None | “entropy” |
1.4 集成学习模型的评价方法
式中:TP代表真阳性(True Positive),即错误样本被预测为错误样本的数量;TN代表真阴性(True Negative),即错误样本被预测为正确样本的数量;FP代表假阳性(False Positive),即正确样本被预测为错误样本的数量;FN代表假阴性(False Negative),即模型错误地将正样本预测为负类的数量。
除上述标量指标外,这里还采用ROC(Receiver Operating Characteristics)曲线[34]以动态直观地显示集成学习模型在不同阈值下的真阳性(收益)和假阳性(成本)之间的相对权衡。即根据ROC曲线及其与坐标轴围成面积也就是AUC分数(Area Under the Curve)来揭示机器学习模型的预测性能。
时间成本也是反映模型性能的重要指标。具体来说,模型的时间成本是指在测试数据集上执行1 000次预测任务所需的时间,相当于模型对1 513 000条轨迹进行预测的总时间。
2 结果与分析
从逻辑上讲,机器学习方法的预测性能取决于数据集所包含的关键信息。
2.1 数据集的特征
为了进一步理解数据集的参数化特征与分类标签之间的相关性,我们采用了斯皮尔曼秩相关系数(Spearman's rank correlation coefficient)来判断参数化特征之间或参数化特征与标签之间的相关性。鉴于参数化特征与分类标签的概率分布不满足正态分布,故采用该统计方法来揭示数据集的性能。
图4以相关矩阵的形式展示了斯皮尔曼秩相关系数的结果。每个元素的值代表显著性检验的P值,相应的颜色代表相关系数。单元格的颜色与相关系数的绝对值成正比。颜色越深,相关系数越高;颜色越浅,相关系数越低。在本文的轨迹数据集中,轨迹的平均水平速度(X1)和轨迹的合速度的平均值(X3)呈现强负相关性而平均垂直速度与平均水平速度之间、平均垂直速度与平均合速度之间不存在相关关系。这与跃移轨迹的基本特征相吻合,即跃移过程以气流对颗粒水平动量输送为主,因而在颗粒总动量中以水平动量为主。颗粒垂直速度往往比水平速度低一个数量级,这样颗粒合速度与水平速度的相关性更明显。出乎意料的是,数据集的4个特征与轨迹分类标签之间显然没有相关性。这反映了上述的沙粒轨迹特征与轨迹的标签之间属于非线性关系,也就是说,上述任何特征不足以作为衡量轨迹正确与否的确定标准。正因为跃移轨迹复杂性,一条轨迹不同于另外一条轨迹,因而很难用某个单一特征来对跃移轨迹进行分类。然而机器学习模型的魅力所在即它们可以通过集成学习来对跃移轨迹进行分类。
图4

图4
参数化特征和标签的相关矩阵(每个矩阵元素的值代表显著性检验的P值,相应的颜色代表相关系数)
Fig.4
Correlation matrix of features and label (the value of each matrix element represents the P-value of the significance test and the corresponding color represents the correlation coefficient)
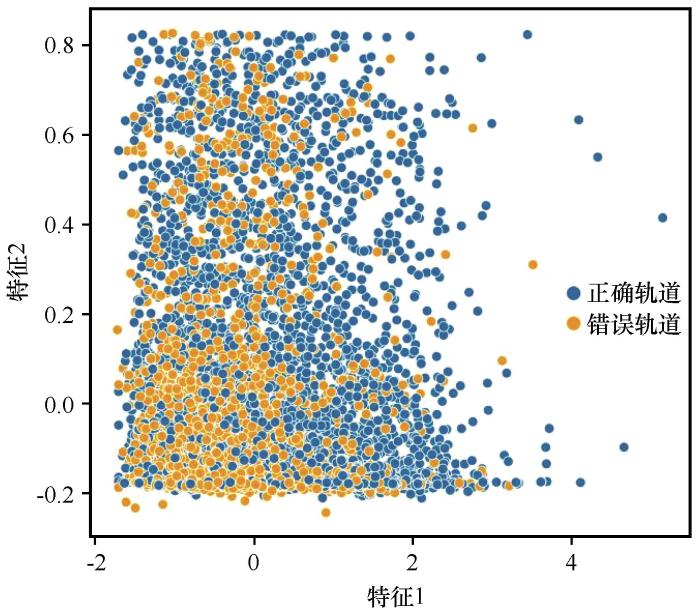
上述数据集所涉及的相关关系及非相关关系共同构成了数据集的“结构”特征。此特征最终影响了机器学习模型的预测表现。同时,采用主成分分析法(Principal Component Analysis,PCA)分析了该数据集对跃移轨迹分类的区分度。图5表明正确轨迹和错误轨迹在二维图像上“共存”,并且在横坐标区间[-2,1]聚集密度相对更高,这说明了本文数据集的区分度还有待改进。因而在未来的工作中,需要建立富有区分度的参数化方案来提高训练数据集的区分度。
图5
2.2 集成模型的预测表现
表3显示极度随机树的准确率(0.9035)、精确度(0.9030)、召回率(0.9035)、F1分数(0.8995)和MCC(0.7378)均高于另外3种算法。其中,MCC作为综合指标,极度随机树比随机森林、梯度提升决策树和XGBoost分别高4.56%,2.37%和1.53%,这表明极度随机树相较于其他算法具有更强的鲁棒性。值得注意的是,相比于梯度提升决策树,XGBoost的准确率、精确度、召回率、F1分数和MCC分别提升了0.21%,0.47%,0.21%,0.11%和0.83%,这也说明XGBoost诸多改进策略的有效性。
表3 4种集成学习模型的表现
Table 3
| 模型 | 准确率 | 精准度 | 召回率 | F1分数 | MCC |
|---|---|---|---|---|---|
| 随机森林 | 0.8923 | 0.8939 | 0.8923 | 0.8857 | 0.7056 |
| 极度随机树 | 0.9035 | 0.9030 | 0.9035 | 0.8995 | 0.7378 |
| 梯度提升决策树 | 0.8976 | 0.8970 | 0.8976 | 0.8929 | 0.7207 |
| XGBoost | 0.8995 | 0.9012 | 0.8995 | 0.8939 | 0.7267 |
如前所述,尽管在优化模型的数据集中,单个特征与轨迹分类没有相关性,但整个数据集表现出了集成性。即单个特征不足以区分轨迹的对错,但这些特征集成后对模型进行了优化,进而使得模型均表现出了可以接受的预测结果,这反映了集成学习模型在解决非线性关系的识别问题的优势。也就是说,文中涉及的集成模型能对绝大多数跃移轨迹进行正确的分类,而这是任何传统的统计方法难以做到的,体现了机器学习的魅力。
图6
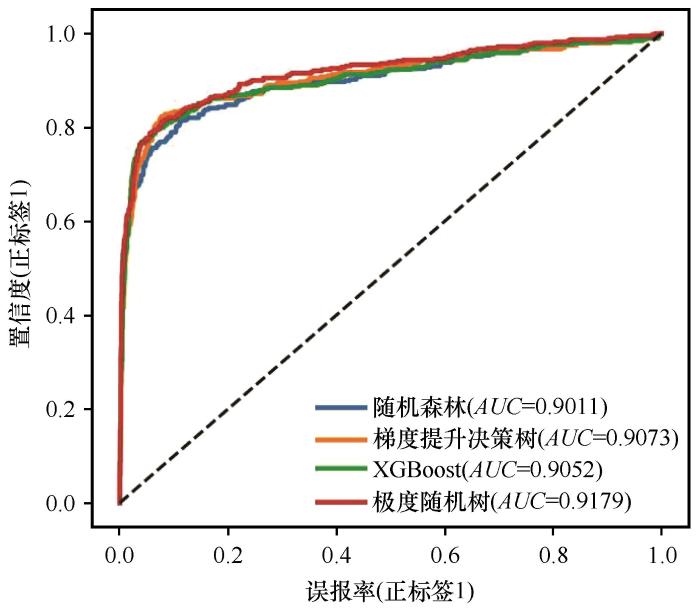
2.3 时间成本
图7表明极度随机树的时间成本最高,为52.74 s,而性能略差于极度随机树的XGBoost的时间成本仅有2.22 s,仅为极度随机树的4.21%,在未来沙粒轨迹追踪算法设计中值得推荐。
图7

综上所述,极度随机树具有更好的预测性能和较高的时间成本,更适合用于离线跃移轨迹分类;具有较好预测表现和较低时间成本的XGBoost更适合用于实时性需求更高的跃移轨迹追踪算法的设计中。
3 讨论
考虑到机器学习模型的预测表现对训练数据集的依赖性,这里对前述数据集进行了优化。具体地,在前述数据集中分别添加瞬时水平速度的方差、瞬时水平速度方差和瞬时垂直速度方差等参数化特征(表4),并据此讨论了极度随机树的预测表现。对仅添加了瞬时水平速度方差的数据集而言,极度随机树模型的MCC和AUC分数较原始数据集分别提升了11.70%和3.56%;对同时添加了瞬时水平和垂直速度方差的数据集而言,极度随机树模型的MCC和AUC分数分别提升了13.26%和5.64%,且后者的表现好于前者,这意味着随着刻画轨迹特征参数个数的增加,其对集成学习模型的预测表现有较为明显的提升。
表4 极度随机树在优化数据集上的预测表现
Table 4
| 优化数据集 | 准确率 | 精确度 | 召回率 | F1分数 | MCC | AUC分数 |
|---|---|---|---|---|---|---|
| 原始数据集 | 0.9035 | 0.9030 | 0.9035 | 0.8995 | 0.7378 | 0.9179 |
| 原始数据集+瞬时水平速度的方差 | 0.9332 | 0.9327 | 0.9332 | 0.9329 | 0.8241 | 0.9506 |
| 原始数据集+瞬时水平速度的方差+瞬时垂直速度的方差 | 0.9379 | 0.9372 | 0.9379 | 0.9374 | 0.8356 | 0.9697 |
4 结论
本文提出了基于自建的跃移轨迹数据集的4种集成学习模型,包括随机森林、极度随机树、梯度提升决策树和XGBoost等。模型运行结果表明:所涉及的模型都能够较好地对跃移轨迹进行分类,其中极度随机树具有最好的预测表现[准确率(0.9035)、精确度(0.9030)、召回率(0.9035)、F1分数(0.8995)、MCC(0.7378)、AUC分数(0.9179)]和最高的时间成本(每1 513 000次预测时间成本为52.74 s);XGBoost具有较好的预测准确率和最低的时间成本。这意味着前者可用于离线的沙粒轨迹的自动识别而后者对在线的轨迹追踪算法上更有前景。另外,通过添加瞬时水平和垂直速度方差等参数,能明显地提升极度随机树模型的预测表现,这意味着优化数据集对提升集成模型的预测表现有重要作用。
参考文献
Statistical analysis of sand grain/bed collision process recorded by high‐speed digital camera
[J].
Wind-tunnel experiments of aeolian sand transport reveal a bimodal probability distribution function for the particle lift-off velocities
[J].
Measuring the kinetic parameters of saltating sand grains using a high-speed digital camera
[J].
PTV measurement of the spanwise component of aeolian transport in steady state
[J].
An experimental study of the dynamics of saltation within a three-dimensional framework
[J].
The 3-D spread of saltation sand over a flat bed surface in aeolian sand transport
[J].
Experimental validation of the near‐bed particle‐borne stress profile in aeolian transport systems
[J].
Wind tunnel investigation of horizontal and vertical sand fluxes of ascending and descending sand particles in aeolian sand transport
[J].
Scaling laws in aeolian sand transport
[J].
Reinvestigation of the scaling law of the windblown sand launch velocity with a wind tunnel experiment
[J].
Saltating particles in a turbulent boundary layer:experiment and theory
[J].
A new hybrid algorithm based on Kalman filter-Hungarian algorithm for tracking aeolian saltating particle in the high-speed video
[J].
Extremely randomized trees
[J].
Greedy function approximation:a gradient boosting machine
[J].
Xgboost:a scalable tree boosting system
[C]//
Predicting of dust storm source by combining remote sensing,statistic-based predictive models and game theory in the Sistan watershed,southwestern Asia
[J].
Application of remote sensing techniques and machine learning algorithms in dust source detection and dust source susceptibility mapping
[J].
Mapping of salty aeolian dust-source potential areas:Ensemble model or benchmark models?
[J].
Machine-learning algorithms for predicting land susceptibility to dust emissions:the case of the Jazmurian Basin,Iran
[J].
Identifying sources of dust aerosol using a new framework based on remote sensing and modelling
[J].
Snow avalanche susceptibility mapping using novel tree-based machine learning algorithms (XGBoost,NGBoost,and LightGBM) with eXplainable Artificial Intelligence (XAI) approach
[J].
Land cover classification using extremely randomized trees:a kernel perspective
[J].
Automated classification of estuarine sub‐depositional environment using sediment texture
[J].
Sediment texture and geochemistry as predictors of sub-depositional environment in a modern estuary using machine learning:a framework for investigating clay-coated sand grains
[J].
Application of machine learning in the identification of fluvial-lacustrine lithofacies from well logs:a case study from Sichuan Basin,China
[J].
Algorithms for hyper-parameter optimization
[C]//
Validation and evaluation of predictive models in hazard assessment and risk management
[J].
An introduction to ROC analysis
[J].
Scikit-learn:machine learning in python
[J].
Binary classification performance measures/metrics:a comprehensive visualized roadmap to gain new insights
[C]//
The advantages of the Matthews correlation coefficient(MCC)over F1 score and accuracy in binary classification evaluation
[J].
A survey of hierarchical classification across different application domains
[J].
Spatial modeling of snow avalanche susceptibility using hybrid and ensemble machine learning techniques
[J].
Winter-Spring prediction of snow avalanche susceptibility using optimisation multi-source heterogeneous factors in the Western Tianshan Mountains,China
[J].
Ngboost:natural gradient boosting for probabilistic prediction
[C]//
Some methods for classification and analysis of multivariate observations
[C]//
A density-based algorithm for discovering clusters in large spatial databases with noise
[C]//
Trajectory data classification:a review
[J].

 甘公网安备 62010202000688号
甘公网安备 62010202000688号
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}